|
14583| 5
|
基于micropython的滑动平均滤波器 |
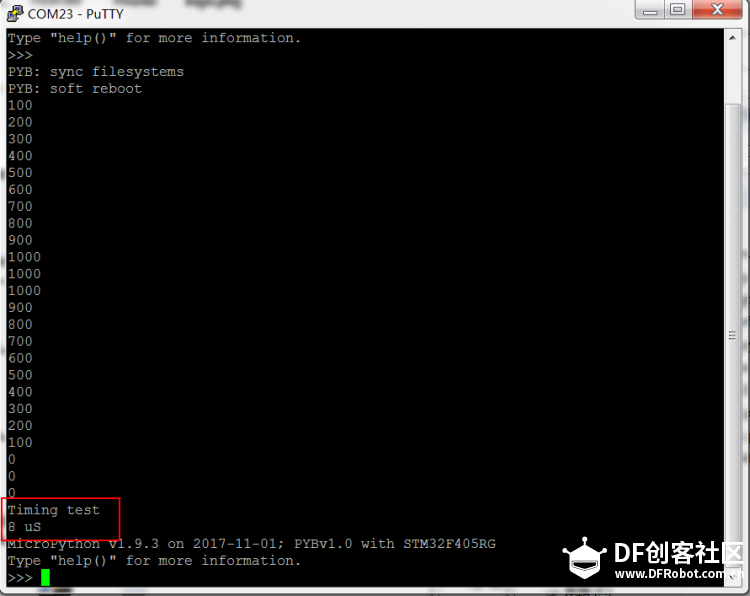
滑动平均滤波也叫递推平均滤波。 以上引用来自互联网,由于出处太多已分不清是谁的原创,如果原作者见了需版权声明请通知  本次实验是基于pyboard的,原码作者是英国一个大牛用汇编写的https://github.com/peterhinch/micropython-filters.git 这个帖子主要对其进行了测试以及用python写了个可以移植到其他micropython平台的代码。后续会贴出FIR滤波器,傅立叶变换等帖子,之前一直想发帖,无奈总是提示我有敏感词汇发不了  下图为官网pyboard的图以及本次测试用的板子图 板子是我自己画板掏钱打板手工焊的,完全兼容其他pyboard的开发板,所以尽管放心测试   英国牛人代码如下, [mw_shl_code=applescript,true]# Implementation of moving average filter in Arm Thumb assembler # Author: Peter Hinch # 15th Feb 2015 # Updated to reflect support for sdiv instruction # Timing: 27uS on MicroPython board (independent of data) # Function arguments: # r0 is an integer scratchpad array. Must be of length 3 greater than # the number of values to be averaged. # On entry array[0] must hold the array length, other elements must be zero # r1 holds new data value # Return value: the current moving average # array[0] is array length, array[1] is the current sum, array[2] the insertion point # r2 holds the length of the coefficient array # Pointers (byte addresses) # r3 start of ring buffer # r4 insertion point (post increment) # r5 last location of ring buffer # Other registers # r7 temporary store for result @micropython.asm_thumb def avg(r0, r1): mov(r3, r0) add(r3, 12) # r3 points to ring buffer start ldr(r2, [r0, 0]) # Element count sub(r2, 4) # Offset in words to buffer end add(r2, r2, r2) add(r2, r2, r2) # convert to bytes add(r5, r2, r3) # r5 points to ring buffer end (last valid address) ldr(r4, [r0, 8]) # Current insertion point address cmp(r4, 0) # If it's zero we need to initialise bne(INIT) mov(r4, r3) # Initialise: point to buffer start label(INIT) ldr(r7, [r0, 4]) # get current sum ldr(r6, [r4, 0]) sub(r7, r7, r6) # deduct oldest value add(r7, r7, r1) # add newest value str(r7, [r0, 4]) # put sum back str(r1, [r4, 0]) # put in buffer and post increment add(r4, 4) cmp(r4, r5) # Check for buffer end ble(NOLOOP) mov(r4, r3) # Incremented past end: point to start label(NOLOOP) str(r4, [r0, 8]) # Save the insertion point for next call ldr(r1, [r0, 0]) # Element count sub(r1, 3) # No. of data points mov(r0, r7) # The sum sdiv(r0, r0, r1) # r0 = r0//r1 [/mw_shl_code] 为了提高效率代码是由汇编写的直接操作寄存器。 这个函数入口主要有两个参数,第一个参数为队列的缓存,第二参数为最新的数据,关于第一个参数源码作者有说明,这个参数的长度必须比队列长度的长3,这个参数第一个元素存储着这个参数的总长度,第二元素为N个样本数据的和,第三个元素是数据的插入点(对于第二个第三个元素不需要去操心,用来给汇编提供便利)后面的元素为采样值的缓存。 作者提供了一个测试程序,主要测试了一下这个用汇编写的代码的执行用时,跑一下试试 [mw_shl_code=python,true]# Demo program for moving average filter # Author: Peter Hinch # 12th Feb 2015 import array, pyb from avg import avg data = array.array('i', [0]*13) # Average over ten samples data[0] = len(data) def test(): for x in range(12): print(avg(data, 1000)) for x in range(12): print(avg(data, 0)) def timing(): t = pyb.micros() avg(data, 10) t1 = pyb.elapsed_micros(t) # Time for one call with timing overheads t = pyb.micros() avg(data, 10) avg(data, 10) t2 = pyb.elapsed_micros(t) # Time for two calls with timing overheads print(t2-t1,"uS") # Time to execute the avg() call test() print("Timing test") timing() [/mw_shl_code] 测试结果
队列长度为10,执行用时8微秒,效率挺高的了 那么接下来看看直接接设备进行实时测试看效果怎么样。 思路:外接一个三轴加速度计,取一个轴的数据进行滤波,同时打印原始数据和滤波后的数据做对比(当然板载一个MMA7660三轴加速度计,但是其输出的数值范围太小了,并不是说小数值不能用只是为了提高观察效果我采用了外置的加速度计) 代码如下 [mw_shl_code=python,true]import MPU6050 import array from protocol import * from avg import * from pyb import I2C,UART,delay #golbal data accx_data = array.array('i', [0]*8) #f_acc_data = avg_filiter(accx_data) accx_data[0] = len(accx_data) #hardwareobject uart_port = UART(4,57600) iic = I2C(1,I2C.MASTER) acc_dev = MPU6050.MPU6050(iic) while True: raw_data = acc_dev.read_Accel_z() filter_data = avg(accx_data,raw_data) send_data = data_send(raw_data,filter_data,0,0,0,0,0,0,0) uart_port.write(send_data) delay(20) [/mw_shl_code] 用串口示波器把数据显示出来效果如图 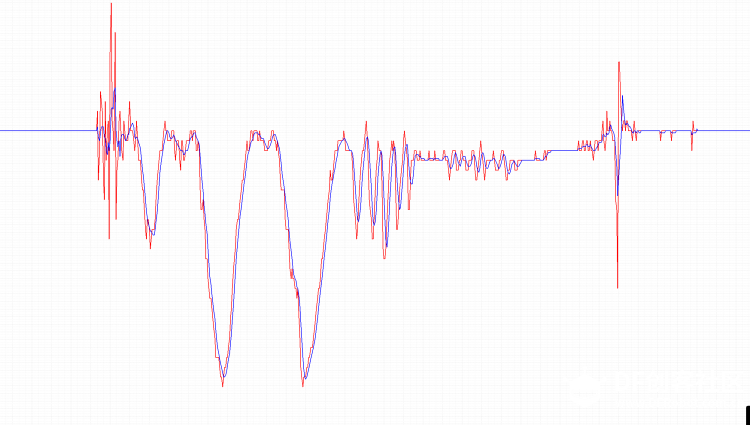 局部图 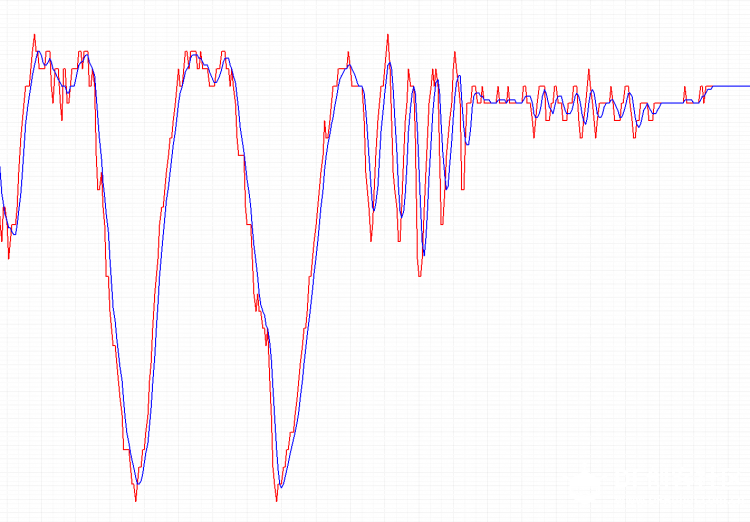 继续放大 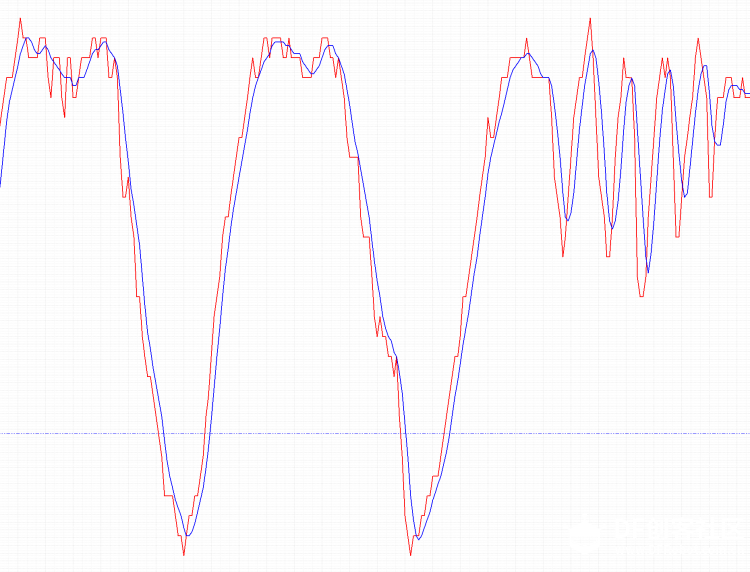 红色是原始数据,蓝色是滤波后的数据,本次实验滑动的N为5,从图像来看确实对波形的毛刺有了很好的平滑效果,波形有轻微的延时  。 。大致思路明白了,那么现在用python自己来写一个滑动滤波的函数,捋一下大致步骤就是,建立一个先入先出的队列,然后每次新的数据入列先把最前面的元素出列然后对所有的数据求平均值,由于对样本的和是一个反复的过程,所以为了提高效率,采纳原作者的思路,找一个位置来存放所求的和,每次计算只需减去最前面的样本在加上最新的样本即可,这样就省去N-2次的加法计算。(我之前用最简单最笨的方法写的试了,实在是耗时太长了,最后借鉴了源作者的方法,换句话说就是对原作者代码的汇编到python的翻译,这样也可以在其他不支持汇编的平台上无缝移植了) 代码如下,但是用时太久了,样本长度为10的情况下测试的。 [mw_shl_code=python,true]import array, pyb class avg_filiter(): def __init__(self,cache_data): self.cache = cache_data self.len = len(cache_data) self.cache[0] = self.len self.sum = 0 for item in cache_data[3:]: self.sum += item self.cache[1] = self.sum def avg(self,new_data): self.cache[1] = self.cache[1] - self.cache[3] self.cache[1] = self.cache[1] + new_data self.cache[3:-1] = self.cache[4:] self.cache[-1] = new_data return self.cache[1]//(self.len - 3) data = array.array('i', [0]*13) # Average over ten samples fdata = avg_filiter(data) def test(): for x in range(12): print(fdata.avg(1000)) for x in range(12): print(fdata.avg(0)) def timing(): t = pyb.micros() fdata.avg(10) t1 = pyb.elapsed_micros(t) # Time for one call with timing overheads t = pyb.micros() fdata.avg(10) fdata.avg(10) t2 = pyb.elapsed_micros(t) # Time for two calls with timing overheads print(t2-t1,"uS") # Time to execute the avg() call test() print("Timing test") timing()[/mw_shl_code] 但是程序耗时整整翻了十倍  不过虽然时间相对汇编来说有点长,但是对于一般的AD采集的场合这个时间完全够用了,现在可以开心的移植到esp8266上了  滑动滤波相对简单一点,大概就这里吧。后面附件贴上代码,里面有mpu6050的库 |
Rockets 发表于 2017-12-27 10:37 一开始实现时没有把和存储起来,这样耗时将近100微秒。其实用micropython开发相当于带着脚镣跳python舞,毕竟受限于他的micro;P |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed



 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶







