|
4182| 0
|
[官方资料] Jetson Nano 2GB系列文章(33):DeepStream 车牌识别与私密信息... |
|
本帖最后由 jetson小助理 于 2021-11-4 11:29 编辑 前一篇文章提到使用deepstream-test的范例代码,修改成“车牌识别”与“遮盖(redaction)”的应用,本文就直接带着大家实现这两个范例的实践,但是并不花时间去解释代码内容,因为基本工作流与逻辑是大致相同的(如下图),就是需要开发人员能够多做实验去熟悉每个插件直接的互动关系。 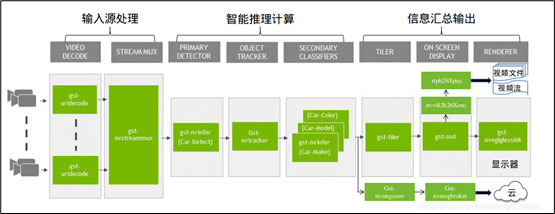
虽然名称上的“redaction”是“修改”的意思,但这里执行的效果其实就是识别视频上的“私人信息”进行遮盖,主要包括“人脸”、“车牌”这些重要信息,因为近年来越来越多的网上小视频的播放,以及个人隐私保护程度高涨,内容提供人如果没有适度地遮盖视频中的隐私信息,很可能遭受到维权的法律诉讼。 因此这个项目虽然看起来并没有太高深的技术含量,但是实用性非常强,在Jetson Nano 2GB上用DeepStream直接帮视频中需要遮盖的信息,进行全自动化的处理,这样就能减少非常多不必要的纠纷。 项目地址在https://github.com/NVIDIA-AI-IOT/redaction_with_deepstream,下面的简易流水线图也相当简单(如下图)。 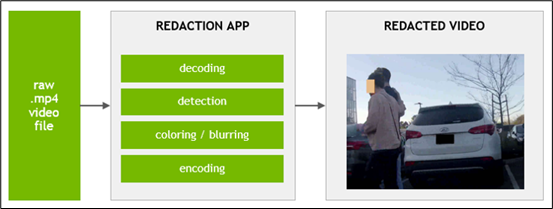 不过比较有参考价值的流水线图在“Pipeline Description”下面的两张图,将整个流水线的内容说明的非常详细,强烈建议读者自行下载去研究,这对于提升对DeepStream流水线的理解是很有帮助的,这部分能连贯起来之后就差不多有足够的掌握程度。 项目执行非常简单,执行以下指令就可以: 如果你的Jetson设备上有安装USB摄像头,执行之后应该就会显示摄像头的画面,看看人头过去的时候是否会把脸遮住? 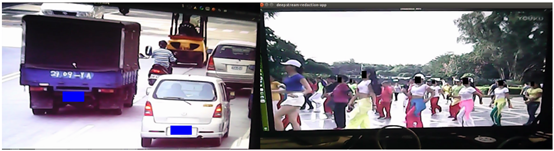 上图就是打开 USB 摄像头,对着电脑屏幕上播放的视频进行测试,左边车牌用蓝色色块遮盖,右边人脸部分用黑色色块遮盖,假如对“遮盖”的颜色不满意,可以调整代码中第109~111行与118~120行的设定值,就可以改变颜色。 您可以自行尝试用视频文件来做输入,并将检测的结果输出成一个视频文件,这部分的指令在开源项目内都有很详细的说明。执行完之后还会显示本次检测的实际性能,在Jetson Nano 2GB上的性能也能到达128FPS,非常好的表现 
这个项目是个很经典的检测器(detector)与分类器(classifier)共同合作的项目,工作原理如下图: 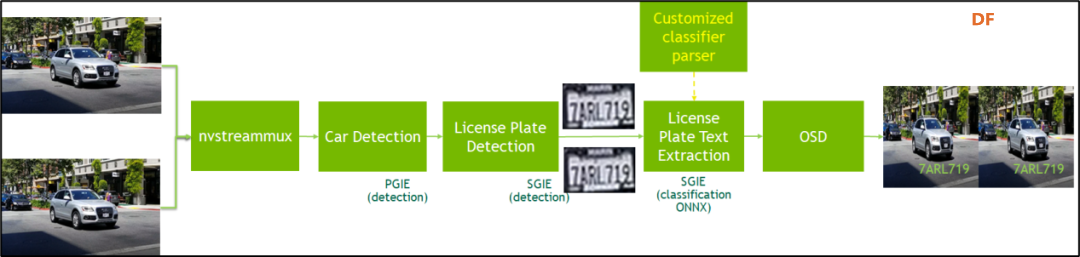
这个项目提供“美国”与“中国”的lpd车牌识别模型与lpr字符分类模型,两组是不能混用的。经过测试,发现在“中国车牌”识别的模型中,应该没有将属于电动车的“绿色”车牌放进去,因此这种车牌也是识别不出来的。 因为deepstream-app这个强大的工具,虽然提供“多检测器”级联的处理功能,但是没有提供“检测器与分类器”级联的功能,因此必须自己撰写代码来实现这个功能。根据的代码内容的风格判断,应该是以deepstream-test2范例为基础进行开发的。 接下来就用这个项目的“中文车牌”识别的部分,带着大家复现一下,里面有些小坑,不过我们都已找到问题的答案,请按照一下步骤执行: 1. 下载项目与模型: 这会从NGC下载三个预训练的中文车牌识别模型文件,以及各自配套的设置文件,脚本为这些模型、配套文件都设置好对应路径,不需要修改: 1) 主检测模型(四分类):resnet18_trafficcamnet_pruned.etlt 2) 次检测模型(一分类):ccpd_pruned.etlt 3) 次分类模型:ch_lprnet_baseline18_deployable.etlt 2. 模型转换: 前面下载的次分类模型(ch_lprnet_baseline18_deployable.etlt)是个中间文件,必须在目标设备(这里是Jetson Nano 2GB)使用tlt-converter转换成该设备能使用的TensorRT加速引擎,需要先到https://developer.nvidia.com/cuda102-trt71-jp45下载cuda10.2_trt7_jp45-xx.zip,解压缩就能看到tlt-converter这个工具。 下载后执行以下转换指令: 再次强调,这个转换步骤必须在目标设备上执行,例如在Xavier上所专换的加速引擎是不能复制到NX或Nano(含2GB)上使用。 3. 编译与修改设定: 直接执行以下指令: 最后,中文版设定文件lpd_ccpd_config.txt里第52行“model-color-format”设定值改为“0”,这样就能正常识别了。 4. 执行: 这个步骤必须您自己去找到合适的视频,或者自行录制一小段视频作为输入,然后在这个目录下执行编译好的执行文件,在deepstream-lpr-app后面需要跟随以下几个参数: 1. 识别种类:1 -> 美国车牌识别、2 -> 中国车牌识别 2. 输出种类:1 -> 输出h264视频文件、2 -> fakesink、3 -> 显示到屏幕上 3. ROI开关:0 -> 关闭、1 -> 开启 4. 输入文件:可以一次给多个.mp4视频文件 5. 最后一个:指定输出.h264视频文件 例如: 下面是使用我们自行在停车场录制的视频、行车记录仪、VisionWorks的范例,总共6个视频文件作为输入的测试结果,提供大家参考。 
本文的重点是要告诉大家,虽然使用deepstream-app调用设定文件的方式是很容易上手,但却没办法解决一些特殊的应用。 本文所介绍的两个实用性非常高的应用,就不能套用这种方式,必须自行撰写代码去执行特殊的处理,分别基于deepstream-test1与deepstream-test2两个C/C++范例去开发,这给了初学者更开放的思路,不能只拘泥于deepstream-app设定文件的配置修改上,应该回归正途从DeepStream的插件流去解决问题。 下一篇文章我们将以NVIDIA在DeepStream 4.0版时所提供的一个Jupyter学习环境,更有条例与有效率地一步一步在deepstrem-test上添加功能,包括将输出的视频流透过RTSP/RTP装向其他设备去显示、多数据源输入、多网络模型组合检测等等功能。 不熟悉C/C++的朋友也不用着急,因为DeepStream也提供相当成熟的Python开发借口与范例,工作原理与C/C++版本完全一致,因此我们还是先用现有资源让大家逐步体验,最后还会再用Python的代码进行示范,这样就能事半功倍。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






