|
2934| 0
|
[官方资料] NVIDIA Jetson Nano 2GB 系列文章(52):图像回归法实现循路功能 |
|
前一篇从 Jetson Projects 所挑选的“TRANSFER LEARNING WITH JETBOT & TRAFFIC CONES”项目,是延续避撞应用使用深度学习的图像分类技术,让 Jetbot 实现循路的功能,这种“定速”类型的操作基本上比较偏向于“找路”或“走迷宫”的应用。 如果要面向“赛道”类的竞速型的循路应用,那么 Jetbot 范例中的 road_following 项目会更加适合,这个项目使用图像回归(Image Regression)的深度学习技术,是一种统计学上非常有用的数学模型。 回归分析(Regression Analysis)在大数据分析中是一种预测性的建模技术,研究因变量(目标)和自变量(预测器)之间的关系,通常用于预测分析、时间序列模型以及发现变量之间的因果关系,例如司机的鲁莽驾驶与道路交通事故数量之间的关系。 在 2018 年有一篇简称为 LDDMM(large deformation diffeomorphic metric mapping,大变形微分同胚度量映射)的基于回归分析的深度学习模型论文(请参考https://arxiv.org/abs/1808.07553),这类摘录作者原文的翻译如下: “本文提出了一种基于大变形差分对称度量映射(LDDMM)和深度神经网络的纵向缺失图像预测回归模型。我们的模型不是直接预测图像扫描,而是预测与基线图像相关的矢量动量序列。该动量序列在 LDDMM 框架中参数化原始图像序列,并位于基线图像的切线空间中,该切线空间是欧几里德的。带有长时短记忆(LSTM)单元的递归网络对矢量动量序列的时间变化进行编码,卷积神经网络(CNN)对矢量动量的基线图像进行编码。由 LSTM 和 CNN 提取的特征被送入解码网络,重建矢量动量序列,通过 LDDMM 拍摄使基线图像变形,用于图像序列预测。为了处理某些时间点的缺失图像,我们在损失计算中采用了二值掩码来忽略其重建。实验结果表明,无论纵向图像序列发生大的或细微的变化,这两个数据集中的时空变化都是有希望的预测。” 这种算法在深度学习领域中的泛用性并不高,但是在处理智能车循路的应用中却是比较常用的,因为“基于时空序列的图像来预测时间序列上缺失图像”的算法,蛮适合赛道型这种不需要过高精确度的快速计算。 这个项目的执行脚本在 jetbot/notebooks/road_following 下面,同样也需要经过“数据收集”、“模型训练”与“现场演示”三个步骤,现在就简单将这三个步骤的重点细节提出来说明一下。 1.数据采集:data_collection.ipynb 或 data_collection_gamepad.ipynb 这里有两个采集的脚本,前者是使用鼠标来标出坐标、后者则是使用前面使用过的游戏摇杆来选取坐标,二者之间没什么差异,不过推荐用鼠标来进行就可以。 前一个循路应用是基于图像分类的技巧,对“整张图形”进行识别来作为决策的依据,虽然最终能展现找路的功能,但本质上还是“避撞”的相同原理。而这里使用的图像回归算法,则要在图像中找出“下一步前往的目标点”,因此在这里只有“选坐标”的步骤而没有“分类”的过程。 有能力的读者可以访问http://www.youtube.com/embed/FW4En6LejhI的视频,会更清楚这个数据采集的过程。下图是执行 data_collection.ipynb 采集数据时会显示的互动界面,左边的图像框是与 Jetbot 的 CSI 镜头同步的画面,我们的任务就是用鼠标在左边图像中点击“下一步要前往”的目标点,然后右边就会截取这个图像,并用绿色圈标识出我们所点击的位置。 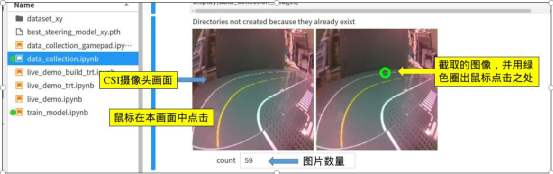 接下来就会在 dataset_xy 目录里存入一个以“xy_x坐标_y坐标_uuid.jpg”的图像文件,然后在互动界面下方的“count”栏里更新数据集的数量。 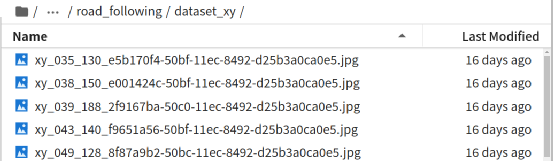 下面 6 组范例截图是在印有“中线”的赛道拼接板上进行采集,这种赛道的采点相对容易,只要点击合适的中线位置就可以。  下面的 6 组范例截图则是在“没有中线”的赛道采集,例如用跳棋子、定位胶带所形成的赛道,这种就需要自行找到大约的位置就行。  至于采点的“远近”问题,就要看所处的“弯度”而定,如果是在直线赛道的位置可以选择较远的距离,如果在弯度较大的地方就选择近一点的距离,注意路线不要造成 Jetbot 车轮压倒边线就可以。 每一次用鼠标点击左边图像框时,就会截取一张带有坐标为档名的图像,需要注意的一个细节,如果过程中有不小心点错的图形,最好立即将它删除掉,因为我们很难在事后根据图像去判别哪些图像是有问题的,很难执行数据清洗的作业,而这些不良的图像会影响最终模型的识别效果。  如果是面对较为复杂的赛道(如上图中),最好全程顺时针与逆时针方向都走过一遍,采集足够的图像;如果是规律性较高的赛道(如上图右),就只要采集 1/4~1/2 的赛道图像也差不多,整个采集量大约在 50~100 张图片就足够。 2.模型训练:train_mode.ipynb 这部分也推荐直接在 Jetson Nano(含2GB)上进行就可以,经过测试在 Jetson Nano 2GB 上对 100 张图片进行 70 回合训练的时间也就 30 分钟左右,并不困难,这个脚本同样会挑选精准度最高的存为 best_steering_model_xy.pth 模型文件,大约 42MB 左右,比前面两个使用图像分类技术的模型要小很多。 整个训练脚本中,除了前置作业需要解析图像文件名所包含的 x, y 坐标信息,还有这里所选择使用的神经网络是 ResNet18,其余处理重点与先前的避撞项目几乎完全一致,没有什么特殊之处。 3.现场演示:live_demo.ipynb 先前使用图像分类法的避撞与找路两个项目,都是属于“定速型”的应用,并且会以自身轴心为重点原地旋转。而 road_following 项目则是让 Jetbot 义无反顾地往前冲,过程中还可以根据赛道弯度去调节 Jetbot 的速度(speed)与转角(steering),这是更加接近我们驾驶车辆的实际状况。 这里使用“比例/微分控制(proportional/derivative control)”算法去动态调节左右电机的转速,这是智能小车领域中相当常用的一种调节行进速度与角度的方法,是个非常成熟的算法,细节请自行在网上查找计算公式。 脚本中一开始导入深度学习模型的操作,与前面的避撞应用是相同的,这里就不重复解说,比较特殊的地方是在脚本中提供三个参数调节滑块,主要如下:
下图是 live_demo.ipynb 执行后,经过调整输出位置的截屏,图左是 Jetbot 的执行状态,其中 x 与 y 值表示当前画面所预测的目标位置,speed 表示 Jetbot 的直线行进速度为全速的百分比,最下面的 steering 表示转向的速度。 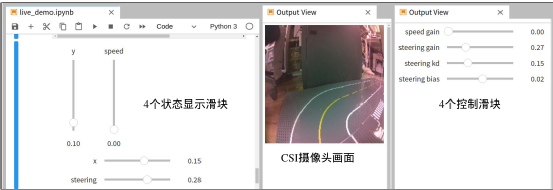 上图中间就是 CSI 摄像头所看到的当前画面,最右边就是可调节的控制滑块,一开始的时候 speed 值尽量小一点,避免让 Jetbot 因为爆冲而损坏,如果沿线运行时的左右摆动幅度太大,可以减小 steering 的值。 事实上这个应用的最终目的,就是将来可以升级到 JetRacer 这类的竞速用途智能车(如下图),因为 JetRacer 所使用的技巧与这个 road_following 是完全一样的,包括从数据采集、模型训练到现场演示的脚本。  但 JetRacer 的机电控制更加复杂,整体成本与组装难度也比 Jetbot 高出许多,因此可以先用这个项目去熟悉竞速车的执行流程与调试细节,未来要升级到 JetRacer 时就能轻松上手,即便不升级硬件,也能用 Jetbot 去体验一下竞速车的乐趣。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






