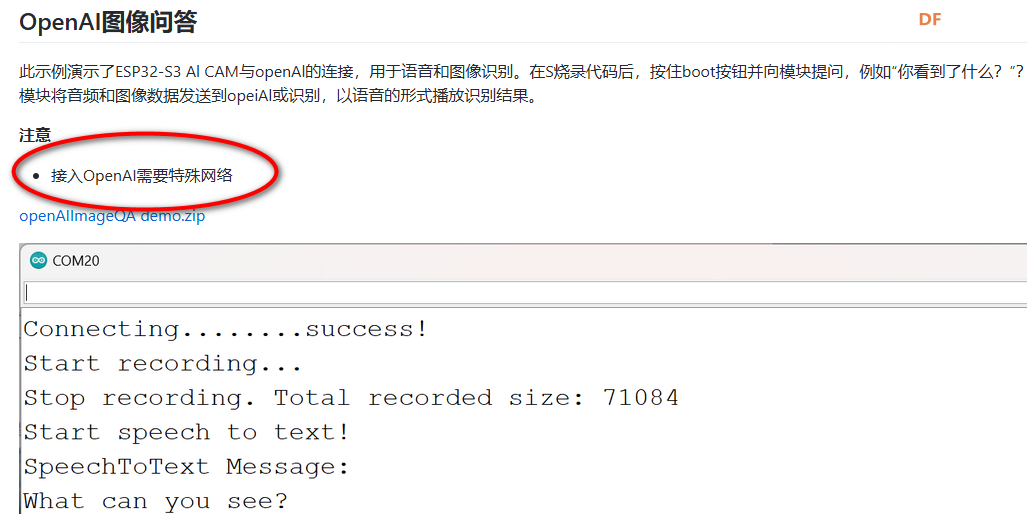
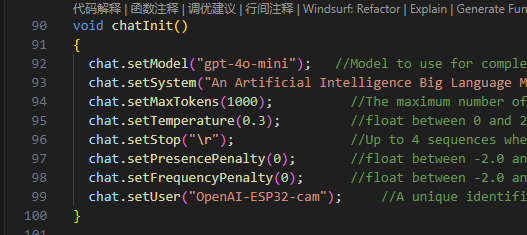
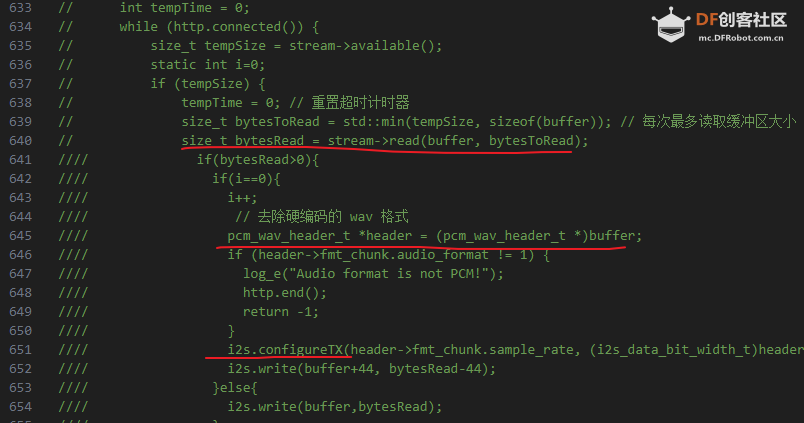
本帖最后由 kylinpoet 于 2025-4-11 16:21 编辑 一、【项目背景】 DF的ESP32-S3 AI CAM产品 (产品链接) ,板载200 W像 素 160 °广角红外夜视摄像头, MEMS麦克风和功放喇叭,以及基于ESP32的SOC芯片,妥妥的人工智能多模态交互利器。本项目预计通过网络大语言模型实现包括但不限于:语音识别、实时拍照、AI理解生成、语音合成等功能,做一个自主可控的多模态交互机器人 。可用于实际生活的学习交流、视障人士环境理解等。 二、【功能实现】 1. 代码简析: ESP32-S3 AI CAM的文档提供了一个 ( OpenAI图像问答)点击访问 system提示词:An Artificial Intelligence Big Language Model for Everyday Communication,always response in chinese,Your answer should focus on the key and be concise and comprehensive. 复制代码 (这也是,我待会的演示视频里语音播放会慢的原因)。 和小智对话机器人相比,我没有使用 websocket进行语音流接收,因此不是实时对话。(当然这只是演示实现,具体功能可后期再完善)2. 完整代码: int OpenAI::audio_post(const String& endpoint, const String& jsonBody) {
log_d(""%s": %s", endpoint.c_str(), jsonBody.c_str());
// 初始化I2S
I2SClass i2s;
i2s.setPins(45, 46, 42);
// pinMode(41, OUTPUT);
if (!i2s.begin(I2S_MODE_STD, 24000, I2S_DATA_BIT_WIDTH_16BIT, I2S_SLOT_MODE_MONO)) {
log_e("MAX98357 initialization failed!");
return -1;
}
// WiFiClientSecure client;
HTTPClient http;
http.setTimeout(60000);
http.useHTTP10(true);
http.begin(base_url + endpoint);
//http.begin("" + endpoint);
http.addHeader("Content-Type", "application/json");
http.addHeader("Authorization", "Bearer " + api_key);
int httpCode = http.POST(jsonBody);
int totalBytesRead = 0; // 记录总共读取的字节数
if (httpCode != HTTP_CODE_OK) {
log_e("HTTP_ERROR: %d", httpCode);
http.end();
return -1;
}
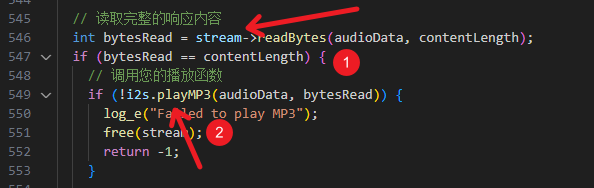
// 获取响应内容
int contentLength = http.getSize();
uint8_t *audioData = (uint8_t *)malloc(contentLength); // 动态分配内存用于存储音频数据
if (audioData == nullptr) {
Serial.println("Failed to allocate memory");
return -1;
}
WiFiClient* stream = http.getStreamPtr();
// 读取完整的响应内容
int bytesRead = stream->readBytes(audioData, contentLength);
if (bytesRead == contentLength) {
// 调用您的播放函数
if (!i2s.playMP3(audioData, bytesRead)) {
log_e("Failed to play MP3");
free(stream);
return -1;
}
} else {
Serial.printf("Failed to read complete audio data, read only %d bytes\n", bytesRead);
}
http.end();
free(audioData); // 释放分配的内存
return bytesRead; // 返回实际解码数据大小
} 复制代码 三、【功能演示】 
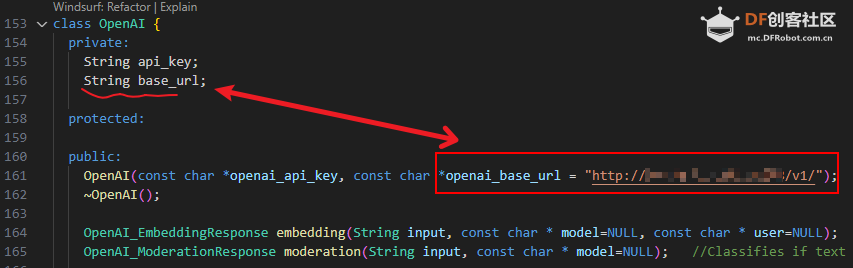
 ),你可以搜索替换。
),你可以搜索替换。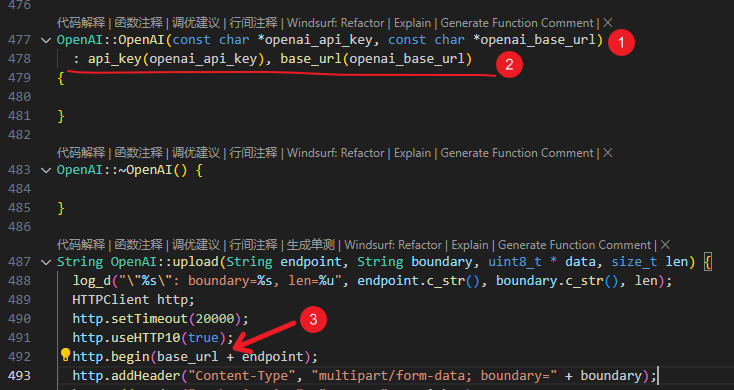



 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






