本帖最后由 kylinpoet 于 2025-5-6 15:57 编辑
一、【项目背景】
DF的ESP32-S3 AI CAM产品(产品链接),板载200W像素160°广角红外夜视摄像头,MEMS麦克风和功放喇叭,以及基于ESP32的SOC芯片,妥妥的人工智能多模态交互利器。本项目借助edgeimpulse平台的优势,训练一个经典剪刀石头布的物体识别模型,对这块板子进行测试。通过本项目主要解决以下几方面的问题:
1. 测试 ESP32-S3 AI CAM 的功能、性能;
2. 学习并使用 edgeimpulse 平台;
3. 了解神经网络模型训练的基本过程;
4. 实现一个简单的石头剪刀布 AI机器人。
二、【功能实现】
1. 数据采集:
原始数据的采集通过wiki上的实例代码实现,这里不再赘述。主要步骤如下:
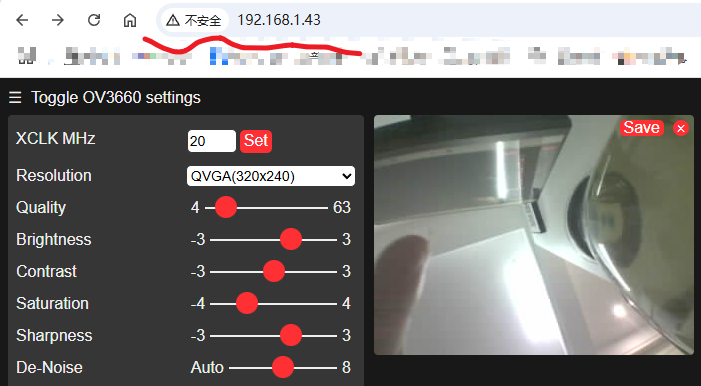
- 烧录"CameraWebServer"示例代码,打开串口监视器查看IP地址
- 局内网内的设备通过浏览器访问IP,点击start按钮查看图像画面
刷入成功后,我们会在串口中看到wifi连接信息。访问相应地址后,我们会看到以下内容。
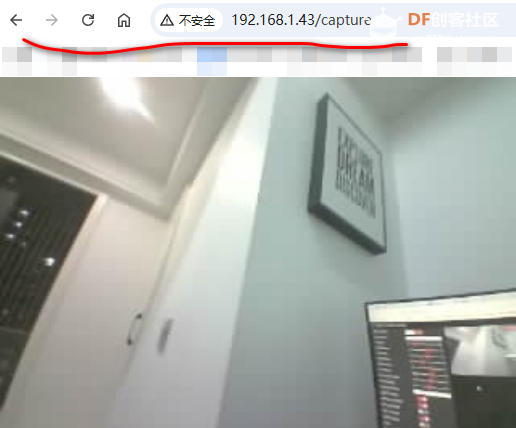
以防有的同学不知道,这里特别说明下:访问 /capture 子页面,可以抓取实时图片。所以我们对数据进行采集时,只要实时抓取这个地址返回的信息即可。当然,也可以修改CameraWebServer 的代码直接采集数据,但这样改动较大不是很方便,因此我专门用python写个了程序抓取:
- import requests
- import time
- import os
- from datetime import datetime
-
- # 设置配置
- ESP_EYE_URL = "http://192.168.1.43/capture" # ESP-Eye的图像捕获URL
- SAVE_DIRECTORY = "esp_eye_images" # 保存图像的文件夹
- CAPTURE_INTERVAL = 0.8 # 捕获间隔(秒)
-
- # 确保保存目录存在
- if not os.path.exists(SAVE_DIRECTORY):
- os.makedirs(SAVE_DIRECTORY)
- print(f"创建目录: {SAVE_DIRECTORY}")
-
- def capture_image():
- # scissors, paper, rock
- """从ESP-Eye捕获图像并保存到指定的文件夹"""
- try:
- # 发送HTTP请求获取图像
- response = requests.get(ESP_EYE_URL, timeout=10)
-
- # 检查请求是否成功
- if response.status_code == 200:
- # 生成带有时间戳的文件名
- timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
- filename = f"{SAVE_DIRECTORY}/rock_{timestamp}.jpg"
-
- # 将图像内容写入文件
- with open(filename, "wb") as f:
- f.write(response.content)
-
- print(f"图像已保存: {filename}")
- return True
- else:
- print(f"请求失败,状态码: {response.status_code}")
- return False
-
- except requests.exceptions.RequestException as e:
- print(f"请求错误: {e}")
- return False
- except Exception as e:
- print(f"发生错误: {e}")
- return False
-
- def main():
- """主函数,循环捕获图像直到达到指定次数"""
- MAX_CAPTURES = 50 # 最大捕获次数
- capture_count = 0 # 当前捕获次数计数器
-
- print(f"开始从 {ESP_EYE_URL} 捕获图像...")
- print(f"图像将保存在 {os.path.abspath(SAVE_DIRECTORY)} 文件夹中")
- print(f"捕获间隔: {CAPTURE_INTERVAL} 秒")
- print(f"将捕获 {MAX_CAPTURES} 张图像后停止")
-
- try:
- while capture_count < MAX_CAPTURES:
- capture_success = capture_image()
- if capture_success:
- capture_count += 1
- print(f"已完成 {capture_count}/{MAX_CAPTURES} 次捕获")
- else:
- print(f"捕获失败,继续尝试 ({capture_count}/{MAX_CAPTURES})")
-
- # 即使捕获失败也等待指定的间隔时间
- time.sleep(CAPTURE_INTERVAL)
-
- print(f"\n已完成 {MAX_CAPTURES} 次捕获,程序结束")
- except KeyboardInterrupt:
- print(f"\n程序已停止,完成了 {capture_count}/{MAX_CAPTURES} 次捕获")
-
- if __name__ == "__main__":
- main()
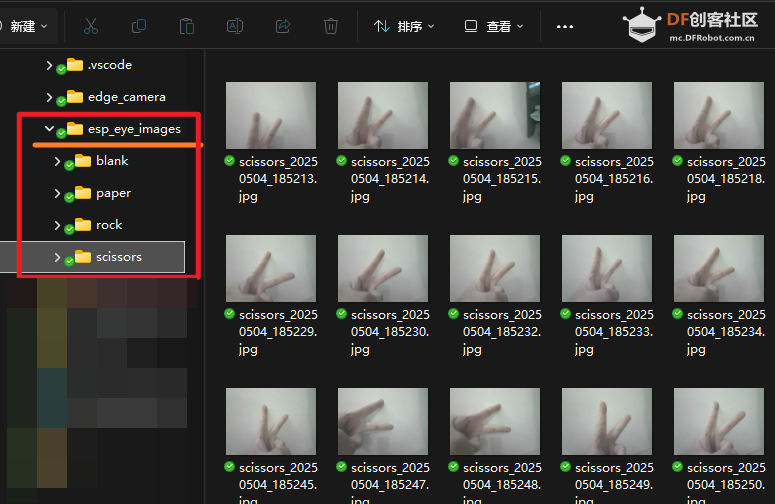
程序运行后,会自动获取 CAM 返回的 50 张图片,并保存在程序目录。为区分不同物体,我们可以创建不同文件夹进行保存。
2. edgeimpulse平台处理
数据采集完成后,我们可以创建一个项目,然后将数据上传到平台:
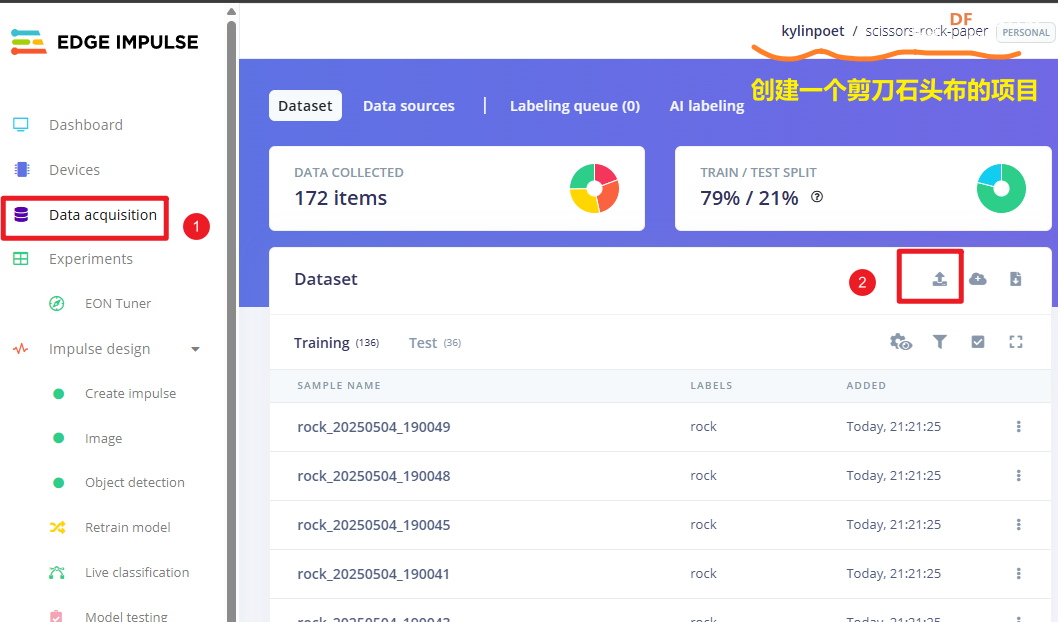
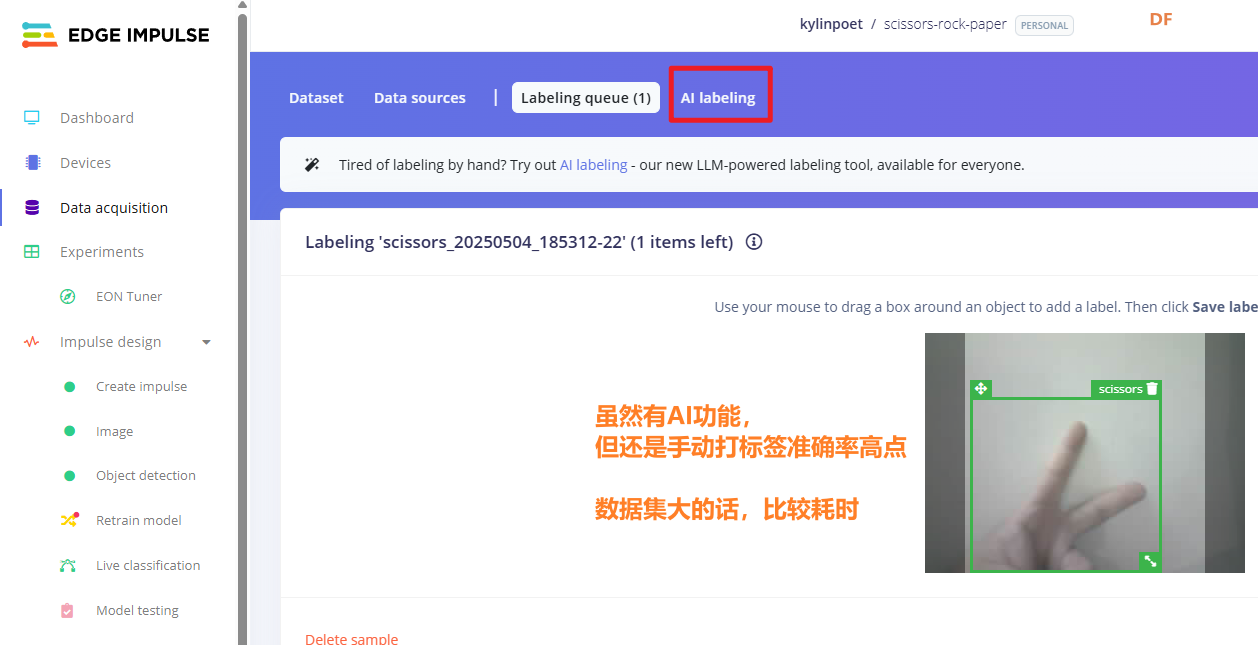
虽然平台的数据标签功能比较强,但数据量大的话,打标签还是需要点时间的。
3. 训练模型
完成所有数据的处理后,接下来我们进行模型训练。大家可以看到标签打完后,会自动生成分类标签。我第一次用以为要添加背景分类,所以会有一个 blank 分类。但实际上,平台会自动处理没有分类标签的图片。(所以这个 blank 标签是没有意义的,但我已经上传了,就保留不删除了)
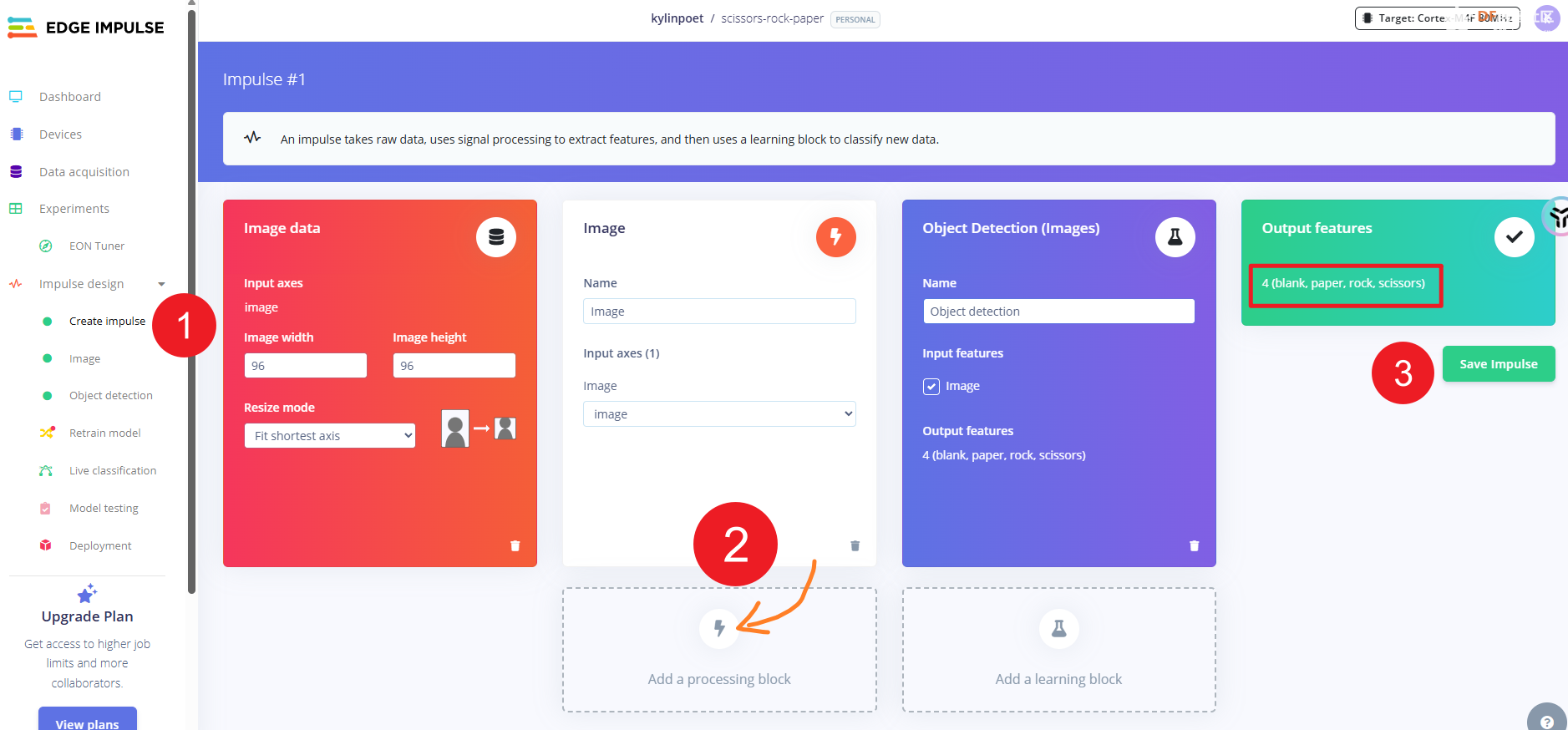
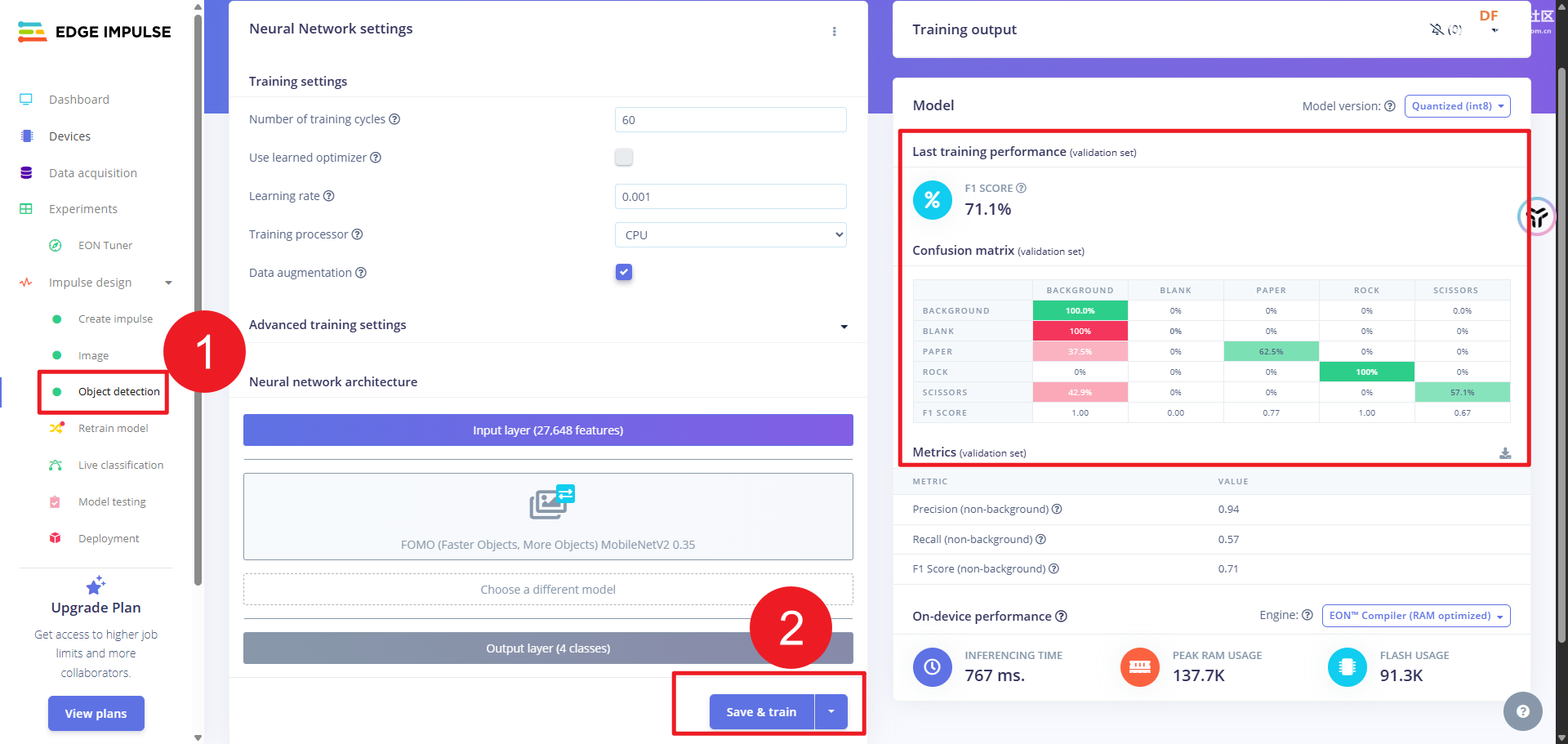
相关设置完成后,就可以直接在平台里训练了。(如果想要了解更细节的东西,同学们可以参考 DF的wiki实例,这里不多做介绍),在下图中大家可以看到训练的结果有个background标签,就是自动生成的。另外,识别率不高,和我的数据采集过程以及标签打得比较随意有关(手动狗头)
4. 部署模型
- 将训练完成的模型库文件解压到"Arduino->libraies"中
- 替换"src\edge-impulse-sdk\tensorflow\lite\micro\kernels"中的"depthwise_conv.cpp"和"conv.cpp"文件
- 将edge_camera文件夹及其子文件移动到模型库文件的examples中
- 打开arduino IDE,选择edge_camera示例,将代码中的第一行改为模型库的.h文件,填入WiFi账号密码,然后编译烧录
- 打开串口监视器即可看到IP地址和识别结果,访问IP即可看到摄像头画面
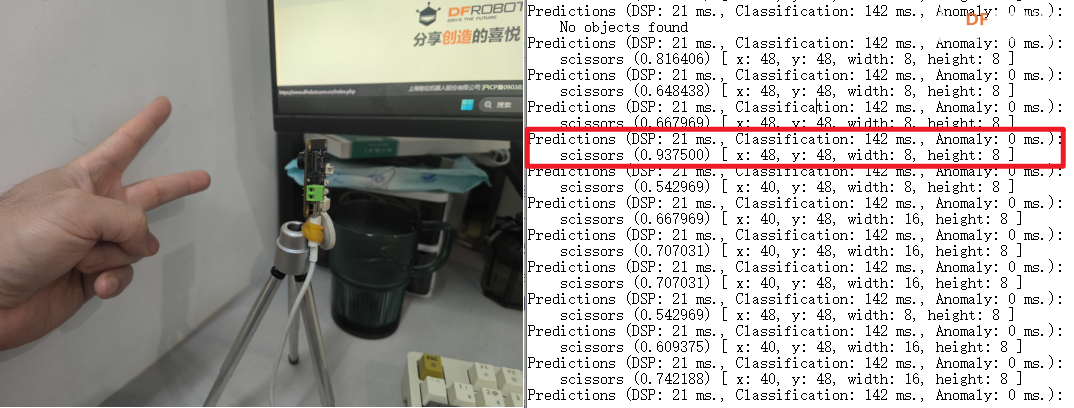
我们可以看到,识别率从 0.5 到 0.9 不等,基本上满足要求。
三、【项目总结】
通过本项目的创作,我们可以发现借助 ESP32-S3 AI CAM 提供的硬件以及 edgeimpulse 平台的软件支持,我们不需要强大的算力和设备就可以完全实现基于神经网络的图像识别。实际上,因为 ESP32-S3 AI CAM 有录放音芯片, edgeimpulse 平台提供声音训练支持,这两个工具也可以用来进行声音数据的识别处理,当然这会在下一篇文章里呈现了。
唯一有问题的是,以上操作需要一定的代码功底以及较强的动手能力,期待 DF 工程师们能简化操作,得以在 Mind+ 上让更多的学生也能用上这个强大的功能。
四、【后续】
为了增加一点交互效果,我在识别成功的基础上加了一些代码,主要是识别成功后进行播报。当然可以加入机器人随机生成剪刀石头布进行判定,以及增加装置等,这个留待同学们实现了。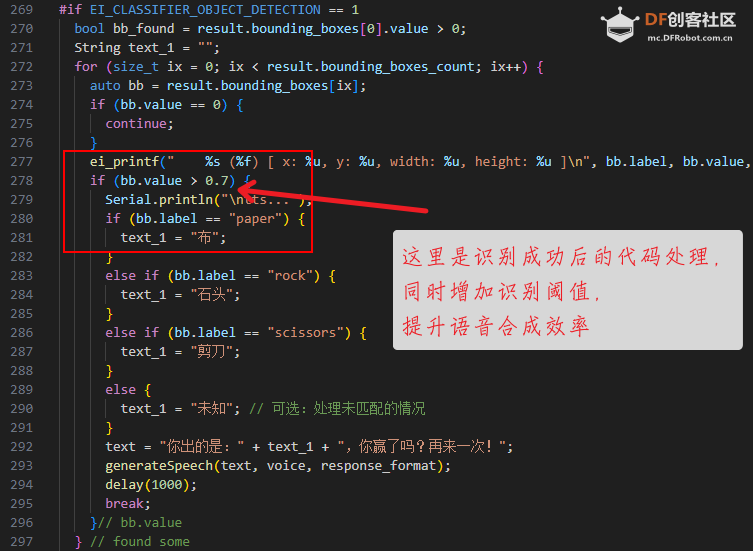
- if (bb.value > 0.7) {
- Serial.println("\ntts...");
- if (bb.label == "paper") {
- text_1 = "布";
- }
- else if (bb.label == "rock") {
- text_1 = "石头";
- }
- else if (bb.label == "scissors") {
- text_1 = "剪刀";
- }
- else {
- text_1 = "未知"; // 可选:处理未匹配的情况
- }
- text = "你出的是:" + text_1 + ",你赢了吗?再来一次!";
- generateSpeech(text, voice, response_format);
- delay(1000);
- break;
- }// bb.value
- } // found some
-
-
- int generateSpeech(String text, String voice, String format) {
- // WiFiClientSecure client;
- const String& url = "http://自相关语音合成网址/v1/audio/speech";
- HTTPClient http;
- http.setTimeout(60000);
- http.useHTTP10(true);
-
- http.begin(url);
- //http.begin("" + endpoint);
- http.addHeader("Content-Type", "application/json");
- http.addHeader("Authorization", "Bearer 合适的验证key");
- DynamicJsonDocument doc(1024);
- doc["input"] = text;
- doc["voice"] = voice;
- doc["response_format"] = format;
-
- // // Add instructions if provided
- // if (instructions.length() > 0) {
- // doc["instructions"] = instructions;
- // }
-
- // Serialize JSON
- String payload;
- serializeJson(doc, payload);
- Serial.println("Sending HTTP POST request...");
- log_i("payload: %s" , payload.c_str());
- int httpCode = http.POST(payload);
- int totalBytesRead = 0;
-
- if (httpCode != HTTP_CODE_OK) {
- log_e("HTTP_ERROR: %d", httpCode);
- http.end();
- return -1;
- }
-
-
- int contentLength = http.getSize();
- uint8_t *audioData = (uint8_t *)malloc(contentLength);
- if (audioData == nullptr) {
- Serial.println("Failed to allocate memory");
- return -1;
- }
- WiFiClient* stream = http.getStreamPtr();
-
-
- int bytesRead = stream->readBytes(audioData, contentLength);
- if (bytesRead == contentLength) {
-
- if (!i2s.playMP3(audioData, bytesRead)) {
- log_e("Failed to play MP3");
- free(stream);
- return -1;
- }
-
-
- } else {
- Serial.printf("Failed to read complete audio data, read only %d bytes\n", bytesRead);
- }
- http.end();
- free(audioData);
- return bytesRead;
- }
这里使用了 LLM 语音合成接口。当然,因为语音是固定的,可以直接在SD卡中预设。
| 



 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






