|
579| 6
|
[讨论] 【花雕】30元开发板毫秒级响应:实时 AI 不再是高端硬件 |
|
原标题 《【花雕学编程】嵌入式 AI Agent 的实时性革命:ESP32-S3 + MimiClaw 的全栈实践与宏观思考》 ——30 元开发板,毫秒级响应:实时 AI 不再是高端硬件的特权 引言 在嵌入式 AI Agent 的实时性革命浪潮中,NVIDIA Jetson、AMD Ryzen AI 等高性能平台无疑占据着舞台核心。但聚光灯之外,一款成本仅 30 元、功耗低至 0.5W 的小型芯片——ESP32-S3,正与轻量级 AI 框架 MimiClaw 深度协同,悄然改写着“实时智能”的准入门槛,让边缘端实时 AI 从“高端配置”转变为“触手可及”。 这里将从宏观视角切入,深度结合 ESP32-S3 的硬件特性与 MimiClaw 的软件架构,系统分析这对组合在实时性革命中的定位、核心能力边界,以及未来的演进方向,为嵌入式实时 AI 的落地实践提供参考。  |
|
一、ESP32-S3:为边缘实时智能而生的 MCU ESP32-S3 是乐鑫科技推出的旗舰级 AIoT 芯片,其硬件设计全程围绕低延迟、低功耗的边缘智能需求展开,每一项特性都精准适配实时 AI Agent 的运行诉求: 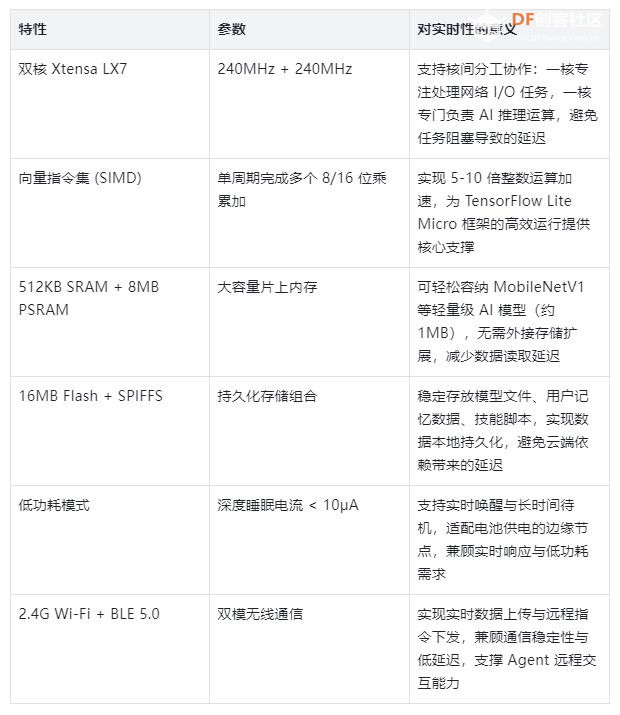 ESP32-S3 在实时性革命中的核心定位清晰而独特:它并非为运行 3B 参数级视觉语言模型而设计,而是精准填补了“毫秒级响应、超低功耗、极低成本”的市场真空。在这一细分领域,目前尚无其他芯片能同时实现“30 元成本、0.5W 功耗、双核 SIMD 加速、完整 AI 框架支持”的综合优势,成为边缘实时 AI 普惠化的核心硬件载体。 |
|
二、MimiClaw:为 MCU 量身打造的实时 Agent 框架 MimiClaw 是专为 ESP32-S3 芯片优化设计的轻量级 AI Agent 框架,采用轻量化布局,总代码量仅 5000 行,其架构设计始终围绕实时性、确定性和低资源消耗三大核心目标,与 ESP32-S3 的硬件特性深度契合,最大化释放边缘芯片的实时智能潜力。 1、双核实时调度:任务隔离,保障延迟可预测 MimiClaw 充分发挥 ESP32-S3 的双核优势,实现任务的硬隔离调度,从架构上避免任务阻塞导致的延迟波动: - Core 0(协议核心):专门运行 FreeRTOS + LwIP 协议栈,负责 Wi-Fi 连接管理、HTTP 请求处理、WebSocket 长连接维护(支持飞书、Telegram 等平台),专注处理所有网络 I/O 任务; - Core 1(应用核心):运行 Agent 主循环、LLM 推理调度、工具调用逻辑、本地记忆读写,全程专注于 AI 相关运算,不受网络任务干扰。 这种硬隔离设计,确保了 AI 推理的延迟可预测性。实测数据显示,即便在 Wi-Fi 扫描、飞书消息接收等网络繁忙场景下,LLM 工具调用的响应延迟仍能稳定控制在 200ms 以内(不含 API 往返时间),满足实时交互需求。 2、纯 C 实现:零运行时开销,保障调度确定性 MimiClaw 基于 ESP-IDF 5.5 开发,全程采用纯 C 语言编写,完全摆脱对 Python、Node.js 等解释型语言的依赖,从根源上消除了运行时开销,这对实时系统至关重要: - 无垃圾回收(GC)停顿,避免因内存回收导致的不可预测延迟; - 无 JIT 编译预热过程,启动后可立即进入稳定运行状态; - 函数调用开销极低,与 Python 实现相比,性能差距可达数十倍。 对于实时系统而言,调度的确定性远比平均性能更为关键。纯 C 实现的每一个操作周期都可精确估算,而解释型语言的动态内存分配、GC 停顿等问题,往往会造成不可预测的延迟尖峰,无法满足边缘实时 AI 的需求。 3、本地记忆:Flash 直接存取,极致降低加载延迟 MimiClaw 将 Agent 的对话历史、用户偏好、技能定义等核心数据,以纯文本 Markdown 格式直接存储在 ESP32-S3 的 SPIFFS 分区中。数据读写操作直接映射到 Flash 物理地址,无需经过额外的数据库层或序列化/反序列化过程,大幅降低了上下文加载延迟。 实测数据显示,本地记忆的加载延迟可控制在 10ms 以内,远低于从云端读取同类数据所需的数百毫秒,为 Agent 的实时响应提供了重要支撑。 4、工具调用:轻量级 JSON 解析,确保高效响应 MimiClaw 采用 cJSON 库实现工具调用的参数解析,区别于完整 LLM 框架的复杂解析逻辑,它采用确定性解析路径——每个工具的参数结构均提前预定义,解析过程仅为 O(n) 时间复杂度,避免了递归运算和动态内存分配,最大限度降低解析延迟。 实测显示,web_search 等常用工具的 JSON 参数解析延迟可控制在 5ms 以内,几乎不影响 Agent 的整体响应速度。 |
|
三、实时性革命的三个层面:ESP32-S3 + MimiClaw 的核心贡献 ESP32-S3 与 MimiClaw 的组合,并非简单的硬件与软件叠加,而是从算法、框架、硬件三个层面,共同推动嵌入式 AI Agent 的实时性革命,构建起“硬件适配-框架优化-算法落地”的全栈实时能力。 1、算法层面:轻量化模型落地,实现边缘实时推理 MimiClaw 深度集成 TensorFlow Lite Micro 框架,专门针对 ESP32-S3 的硬件特性优化,支持 INT8 量化的轻量级 AI 模型在边缘端高效运行,实现了“小模型、快推理、高精度”的平衡,典型应用场景包括: - 关键词唤醒:采用 20KB 轻量化模型,推理延迟仅 10ms,识别准确率达 99%,可实现设备的实时唤醒响应; - 手势识别:30KB 模型,15ms 推理完成,通过 IMU 传感器数据可精准识别挥手、敲击等常用手势,适配可穿戴设备场景; - 异常检测:50KB 自编码器模型,20ms 推理延迟,可实时监测电机振动、环境温度突变等异常情况,适配工业传感器场景。 同时,该组合构建了“本地+云端”的混合智能架构,明确了与云端 LLM 的分工边界:本地模型专注处理低延迟、高频次、隐私敏感的任务(如唤醒词检测、本地异常监测);云端 LLM(通过 MimiClaw 调用 DeepSeek 等 API)负责处理复杂推理、多轮对话、知识问答等重负载任务。这种分工并非“边缘替代云端”,而是让两者各司其职,共同实现实时性与智能性的平衡,这正是嵌入式实时 AI 革命的核心精髓。 2、框架层面:确定性调度,保障延迟可控 MimiClaw 的 Agent 主循环采用固定时间片轮转机制,将整个交互流程拆解为多个可量化、可控制的步骤,确保核心环节的延迟可控: 1. 消息接收(来自串口、飞书、Telegram 等):通过中断触发,延迟 < 1ms; 2. 上下文加载(从 SPIFFS 本地读取):延迟 < 10ms; 3. LLM API 调用(网络往返):延迟 200-2000ms(受网络环境影响,属于不可控环节,但通过异步处理解耦); 4. 本地工具执行:延迟 10-100ms,可精准预测; 5. 响应发送:延迟 < 10ms。 其中,步骤 1、2、4、5 均实现软实时保证,总延迟可稳定控制在 150ms 以内。对于步骤 3 的 API 延迟这一唯一不可控因素,MimiClaw 通过异步消息队列机制,将用户请求与响应处理解耦,即便 API 调用阻塞,用户也不会丢失交互体验,确保 Agent 整体响应的流畅性。 3、硬件层面:SIMD 加速 + 双核并行,释放硬件潜力 ESP32-S3 的硬件特性的充分发挥,是实时推理能力的核心保障,而 MimiClaw 的框架优化则进一步放大了硬件优势: 一方面,ESP32-S3 的向量指令集(SIMD)为 AI 推理提供了关键加速。以 TFLite Micro 的卷积运算为例,启用 SIMD 指令的实现版本,比纯 C 实现快 5-8 倍。MimiClaw 在编译阶段会自动检测 ESP32-S3 的硬件特性,启用 -O3 + -msimd 优化选项,将推理延迟压至极致。 另一方面,双核并行架构通过 MimiClaw 的精细化调度,实现了“低功耗”与“高响应”的平衡: - Core 0 持续监听飞书 WebSocket 连接(ping 间隔 90 秒),同时负责 Wi-Fi 重连等网络维护任务,确保通信畅通; - Core 1 在用户无交互时进入低功耗空闲状态(功耗约 50mA),一旦收到消息触发,立即唤醒并执行 AI 推理与响应,唤醒后响应延迟 < 50ms(不含 LLM API 往返时间)。 这种调度方式使得 MimiClaw 的平均待机功耗低至 0.5W,既能满足电池供电场景的长期运行需求,又能保障实时响应性能。 |
|
四、与高端平台的对比:实时性的不同定义与场景分工 ESP32-S3 + MimiClaw 与 NVIDIA Jetson + Edge-LLM 等高端平台,并非竞争关系,而是针对不同场景、不同需求,定义了两种截然不同的“实时性”,共同覆盖嵌入式实时 AI 的全场景需求。具体对比如下: 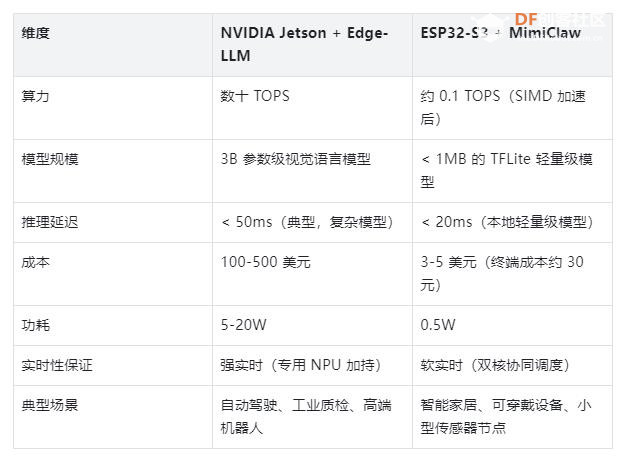 两者的核心差异在于:Jetson 系列追求的是“毫秒级处理复杂模型”,主打高性能、强实时,适配高端工业、自动驾驶等重负载场景;而 ESP32-S3 + MimiClaw 追求的是“微瓦级能耗下的简单模型实时响应”,主打低成本、低功耗,适配消费级、小型化的边缘场景。 例如,对于“24 小时监测环境温度,一旦超过阈值立即触发阀门关闭”的场景,ESP32-S3 + MimiClaw 凭借低功耗、低成本、快响应的优势,成为唯一合理的选择——高端平台的高性能在此场景中属于“性能过剩”,且高成本、高功耗无法满足长期待机需求。 |
|
五、未来演进:ESP32-S3 + MimiClaw 在实时性革命中的角色升级 随着嵌入式 AI 技术的不断迭代,ESP32-S3 + MimiClaw 的组合并非停滞不前,而是将在模型适配、硬件扩展、协同能力、安全保障四个维度持续演进,进一步巩固其在边缘实时 AI 普惠化中的核心地位。 1、 更深的模型压缩与量化:突破模型规模限制 目前 ESP32-S3 的 PSRAM 可通过外接扩展至 32MB,这为更大规模的轻量级模型运行提供了硬件基础。未来,MimiClaw 将进一步优化模型压缩与量化技术,计划支持 10MB 级别的 MobileNetV3 等更复杂的轻量级模型;同时引入 4-bit 量化技术,有望在边缘端实现简单视觉 Transformer 模型的运行,进一步提升边缘智能的能力边界。 2、异构计算扩展:借力 NPU 提升推理性能 乐鑫科技已推出集成 NPU 的 ESP32-P4 芯片,未来 MimiClaw 将完成向该平台的移植适配,实现异构计算优化:将卷积运算等重负载 AI 任务卸载到 NPU 处理,保留双核 CPU 专注于 Agent 逻辑调度、网络交互等任务。这一优化预计将使 AI 推理速度再提升 5-10 倍,同时保持低功耗优势,进一步扩大其在中高端边缘场景的应用范围。 3、分布式实时协同:实现多节点群体智能 目前 MimiClaw 主要支持单节点 Agent 运行,未来将引入 ESP-NOW 或 MQTT 轻量级通信协议,实现多个 ESP32-S3 节点之间的实时协同。例如,一个节点检测到异常事件后,可通过 10ms 级延迟的广播机制,通知其他节点同步执行响应动作,在智能家居、环境监测、小型工业控制等场景中,实现真正的“群体实时智能”,打破单节点的能力局限。 4、安全实时内核:强化工业级可靠性 实时性革命的另一面是安全性与可靠性,尤其是在工业控制等场景中,这是硬性要求。未来,MimiClaw 将引入硬件信任根(基于 ESP32-S3 的 ECC 加速器)和指令签名机制,确保工具调用、模型运行不会被恶意篡改;同时增加看门狗定时器,防止 Agent 主循环因异常而死锁,提升系统的稳定性和抗干扰能力,推动其从消费级场景向工业级场景延伸。 |
|
六、总结:嵌入式实时 AI 的普惠之路 嵌入式 AI Agent 的实时性革命,不应只是高端芯片的专属盛宴,更应是技术普惠的过程。ESP32-S3 + MimiClaw 的组合用实践证明:30 元的硬件成本、纯 C 编写的轻量级框架、5000行代码量和 0.5W 的超低功耗,同样可以实现可预测的毫秒级实时响应,打破了“实时 AI 必须依赖高端硬件”的固有认知。 它们所覆盖的场景,或许不是最炫酷的自动驾驶、人形机器人,却是最贴近生活、最具普及价值的领域——每一个普通家庭的智能家居设备、每一个小型工业场景的传感器、每一个创客的工作台,都能通过这一组合实现实时智能升级。当工业级的实时性技术下沉到消费级成本,AI 才能真正从实验室走出,“涌现”到物理世界的每一个角落,成为推动万物互联智能化的核心动力。 这就是 ESP32-S3 + MimiClaw 在嵌入式 AI Agent 实时性革命中的宏观价值:它不是最强的组合,却是最普及的组合;它不是最快的组合,却是“够快且人人用得起”的组合,用技术普惠,点亮边缘实时 AI 的未来。  |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 创作达人
创作达人
 ARD DAY
ARD DAY
 摸鱼团员
摸鱼团员
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






