|
7337| 13
|
[项目] 【2020】树莓派——语音播报新冠疫情实时数据 |
 【演示视频】 (为视频效果,使用循环播报方式) 此次新型冠状病毒感染的肺炎疫情,不仅给全民造成身体上的危机,还带来心理层面的考验。 疫情本身属于应激性事件。适当的应激反应是必要的,然而,应激不足和应激过度对身心健康和社会情绪稳定都不利。应激不足,表现为思想麻痹大意、反应迟缓,进不了警觉期。而应激过度则表现为应对措施过猛、公众恐慌等。 对于大众而言,如果长时间宅在家中,以及过度暴露在负面信息之下,会出现替代性创伤的现象。铺天盖地的疫情信息会对心理造成一些创伤影响,进而影响个人行为。其中一个表现为,持续不断地看手机,心理会出现紧张、担心、焦虑等情绪,“大家会担心疫情数据是多少,到底什么时候过去等等。” 这是一种对于不可预期事件的焦虑,焦虑的情绪会引发一系列生活问题。情绪和行为相互交织,如果不进行积极的干预,容易形成恶性循环。 所以,我们应该适度关注疫情,不是不关注,也不是一直关注。 为了宅在家里为社会做贡献,适当关注疫情,少看手机,宅在家里为武汉加油!今天我使用树莓派获取实时数据,并定时用语音进行播报。(创意来自Shuuei 大神 ) 【完整程序代码】python2 [mw_shl_code=python,false]# -*- coding: utf-8 -*- import urllib2 import time from datetime import datetime import pygame # pip install pygame from aip import AipSpeech """ 你的 APPID AK SK 均可在百度云语音技术服务控制台中的应用列表中查看。 """ APP_ID = '百度申请的APP_ID ' API_KEY = '百度申请的API_KEY ' SECRET_KEY = '百度申请的SECRET_KEY ' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) def playMusic(filename, loops=0, start=0.0, value=1): """ :param filename: 文件名 :param loops: 循环次数 :param start: 从多少秒开始播放 :param value: 设置播放的音量,音量value的范围为0.0到1.0 :return: """ flag = False # 是否播放过 pygame.mixer.init() # 音乐模块初始化 while 1: if flag == 0: pygame.mixer.music.load(filename) # pygame.mixer.music.play(loops=0, start=0.0) loops和start分别代表重复的次数和开始播放的位置。 pygame.mixer.music.play(loops=loops, start=start) pygame.mixer.music.set_volume(value) # 来设置播放的音量,音量value的范围为0.0到1.0。 if pygame.mixer.music.get_busy() == True: flag = True else: if flag: pygame.mixer.music.stop() # 停止播放 break def speak(content): result = client.synthesis(content, 'zh', 3, { 'vol': 5, }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result) f.close() playMusic('auido.mp3') def timer(n): while True: a = int(time.time()) #当前时间 c = datetime.fromtimestamp(a+86400).strftime('%H:%M') #格式转换 '''#定时播报 if c>'08:05': l=0 if c=='08:00' and l==0: l=1''' if 1:#循环播报 response=urllib2.urlopen("https://news.163.com/special/epidemic/") html=response.read() a=html.find('cover_con') b=html.find('map_block mb') html=html[a:b] html=html.decode('gbk','ignore') title=html[html.find('cover_li')+10:html.find('/span')-1] title1=title[:title.find('<span>')] title2=title[title.find('<span>')+6:] if title2[7]=='0': month=title2[8] else: month=title2[7:9] if title2[10]=='0': day=title2[11] else: day=title2[10:12] if title2[13]=='0': hour=title2[14] else: hour=title2[13:15] minute=title2[16:] title2=title2[:6]+'年'.decode('utf-8')+month+'月'.decode('utf-8')+day+'日'.decode('utf-8')+hour+'时'.decode('utf-8')+minute+'分'.decode('utf-8') html=html[html.find('确诊'.decode('utf-8')):] quezheng=html[html.find('number')+8:html.find('</div>')] html=html[html.find('疑似'.decode('utf-8')):] yisi=html[html.find('number')+8:html.find('</div>')] html=html[html.find('较昨日'.decode('utf-8')):] added=html[html.find('<span>')+6:html.find('</span>')] if added[0]=='+': added='增加'.decode('utf-8')+added[1:] if added[0]=='-': added='减少'.decode('utf-8')+added[1:] html=html[html.find('死亡'.decode('utf-8')):] siwang=html[html.find('number')+8:html.find('</div>')] html=html[html.find('治愈'.decode('utf-8')):] zhiyu=html[html.find('number')+8:html.find('</div>')] print (html) print (title1) print (title2) print (quezheng) print (added) print(datetime.now().strftime("%Y-%m-%d %H:%M:%S")) speak(title1) speak(title2) speak('确诊人数'.decode('utf-8')+quezheng) speak('疑似人数'.decode('utf-8')+yisi) speak('较昨日'.decode('utf-8')+added) speak('死亡人数'.decode('utf-8')+siwang) speak('治愈人数'.decode('utf-8')+zhiyu) time.sleep(n) timer(5) [/mw_shl_code] 1、寻找恰当网站获取实时数据 找到网易:https://news.163.com/special/epidemic/ 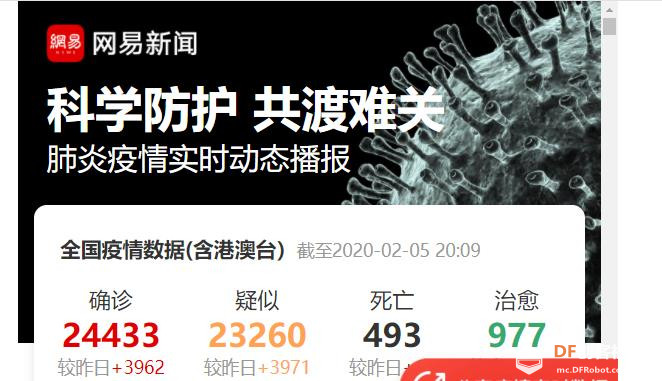 因查看其源码,发现数据比较好获取。  2、获取网页源码 [mw_shl_code=python,false] response=urllib2.urlopen("https://news.163.com/special/epidemic/") html=response.read()[/mw_shl_code] 3、针对数据特点,进行截取 [mw_shl_code=python,false] a=html.find('cover_con') b=html.find('map_block mb') html=html[a:b] html=html.decode('gbk','ignore') title=html[html.find('cover_li')+10:html.find('/span')-1] title1=title[:title.find('<span>')] title2=title[title.find('<span>')+6:] if title2[7]=='0': month=title2[8] else: month=title2[7:9] if title2[10]=='0': day=title2[11] else: day=title2[10:12] if title2[13]=='0': hour=title2[14] else: hour=title2[13:15] minute=title2[16:] title2=title2[:6]+'年'.decode('utf-8')+month+'月'.decode('utf-8')+day+'日'.decode('utf-8')+hour+'时'.decode('utf-8')+minute+'分'.decode('utf-8') html=html[html.find('确诊'.decode('utf-8')):] quezheng=html[html.find('number')+8:html.find('</div>')] html=html[html.find('疑似'.decode('utf-8')):] yisi=html[html.find('number')+8:html.find('</div>')] html=html[html.find('较昨日'.decode('utf-8')):] added=html[html.find('<span>')+6:html.find('</span>')] if added[0]=='+': added='增加'.decode('utf-8')+added[1:] if added[0]=='-': added='减少'.decode('utf-8')+added[1:] html=html[html.find('死亡'.decode('utf-8')):] siwang=html[html.find('number')+8:html.find('</div>')] html=html[html.find('治愈'.decode('utf-8')):] zhiyu=html[html.find('number')+8:html.find('</div>')][/mw_shl_code] 4、利用百度云语音技术对数据转语音mp3,并使用pygame进行朗读 [mw_shl_code=python,false]import pygame # pip install pygame from aip import AipSpeech """ 你的 APPID AK SK 均可在百度云语音技术服务控制台中的应用列表中查看。 """ APP_ID = '百度申请的APP_ID ' API_KEY = '百度申请的API_KEY ' SECRET_KEY = '百度申请的SECRET_KEY ' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) def playMusic(filename, loops=0, start=0.0, value=1): """ :param filename: 文件名 :param loops: 循环次数 :param start: 从多少秒开始播放 :param value: 设置播放的音量,音量value的范围为0.0到1.0 :return: """ flag = False # 是否播放过 pygame.mixer.init() # 音乐模块初始化 while 1: if flag == 0: pygame.mixer.music.load(filename) # pygame.mixer.music.play(loops=0, start=0.0) loops和start分别代表重复的次数和开始播放的位置。 pygame.mixer.music.play(loops=loops, start=start) pygame.mixer.music.set_volume(value) # 来设置播放的音量,音量value的范围为0.0到1.0。 if pygame.mixer.music.get_busy() == True: flag = True else: if flag: pygame.mixer.music.stop() # 停止播放 break def speak(content): result = client.synthesis(content, 'zh', 3, { 'vol': 5, }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result) f.close() playMusic('auido.mp3') [/mw_shl_code] 【2020年3月19日修正】 因获取数据的网站进行了数据显示调整,致使以上代码不能再实时播报。现将代码更正如下: [mw_shl_code=applescript,false]# -*- coding: utf-8 -*- import urllib2 from aip import AipSpeech import pygame # pip install pygame import time from datetime import datetime import requests import json """ 你的 APPID AK SK 均可在服务控制台中的应用列表中查看。 """ APP_ID = '14778722' API_KEY = 'BFoXqkmh5ow7iyYt7A8EWMDo' SECRET_KEY = 'ZfETPvdqpABOgwlTwQRrohFdZRcT4U6N' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) def playMusic(filename, loops=0, start=0.0, value=1): """ :param filename: 文件名 :param loops: 循环次数 :param start: 从多少秒开始播放 :param value: 设置播放的音量,音量value的范围为0.0到1.0 :return: """ flag = False # 是否播放过 pygame.mixer.init() # 音乐模块初始化 while 1: if flag == 0: pygame.mixer.music.load(filename) # pygame.mixer.music.play(loops=0, start=0.0) loops和start分别代表重复的次数和开始播放的位置。 pygame.mixer.music.play(loops=loops, start=start) pygame.mixer.music.set_volume(value) # 来设置播放的音量,音量value的范围为0.0到1.0。 if pygame.mixer.music.get_busy() == True: flag = True else: if flag: pygame.mixer.music.stop() # 停止播放 break def speak(content): result = client.synthesis(content, 'zh', 3, { 'vol': 5, }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result) f.close() playMusic('auido.mp3') def get_data(): url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery341001657575837432268_1581070969707&_=1581070969708' headers = {'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36'} res = requests.get(url, headers=headers).text a = res.split('jQuery341001657575837432268_1581070969707(')[1].split(')')[0] c = json.loads(a) data = json.loads(c['data']) return data def print_data_china(): data = get_data() speak('最新疫情实时数据报告'.decode('utf-8')) speak('统计截至时间:'.decode('utf-8')+str(data['lastUpdateTime'])) speak('全国确诊人数:'.decode('utf-8')+str(data['chinaTotal']['confirm'])) if int(data['chinaAdd']['confirm'])<0: speak('相较于昨天确诊人数:减少'.decode('utf-8')+str(abs(int(data['chinaAdd']['confirm'])))) else: speak('相较于昨天确诊人数:增加'.decode('utf-8')+str(data['chinaAdd']['confirm'])) speak('全国疑似病例:'.decode('utf-8')+str(data['chinaTotal']['suspect'])) if int(data['chinaAdd']['suspect'])<0: speak('相较于昨天疑似人数:减少'.decode('utf-8')+str(abs(int(data['chinaAdd']['suspect'])))) else: speak('相较于昨天疑似人数:增加'.decode('utf-8')+str(data['chinaAdd']['suspect'])) speak('全国治愈人数:'.decode('utf-8')+str(data['chinaTotal']['heal'])) if int(data['chinaAdd']['heal'])<0: speak('相较于昨天治愈人数:减少'.decode('utf-8')+str(abs(int(data['chinaAdd']['heal'])))) else: speak('相较于昨天治愈人数:增加'.decode('utf-8')+str(data['chinaAdd']['heal'])) speak('全国死亡人数:'.decode('utf-8')+str(data['chinaTotal']['dead'])) if int(data['chinaAdd']['dead'])<0: speak('相较于昨天死亡人数:减少'.decode('utf-8')+str(abs(int(data['chinaAdd']['dead'])))) else: speak('相较于昨天死亡人数:增加'.decode('utf-8')+str(data['chinaAdd']['dead'])) def print_data_path_china(): data = get_data()['areaTree'][0]['children'] path_data = [] path_china = [] for i in data: name=i['name'] today = i['today'] total = i['total'] shiji="湖北".decode('utf-8') if name==shiji: huibei='累计确诊人数'.decode('utf-8')+str(total['confirm'])+',相较于昨日确诊人数'.decode('utf-8')+str(today['confirm'])+',累计疑似病例'.decode('utf-8')+str(total['suspect'])+',累计治愈人数'.decode('utf-8')+str(total['heal'])+',累计死亡人数'.decode('utf-8')+str(total['dead']) shiji="上海".decode('utf-8') if name==shiji: shanghai='累计确诊人数'.decode('utf-8')+str(total['confirm'])+',相较于昨日确诊人数'.decode('utf-8')+str(today['confirm'])+',累计疑似病例'.decode('utf-8')+str(total['suspect'])+',累计治愈人数'.decode('utf-8')+str(total['heal'])+',累计死亡人数'.decode('utf-8')+str(total['dead']) path_china.append(i['name']) path_data.append(i['children']) path = '湖北'.decode('utf-8') if path in path_china: num = path_china.index(path) data_path = path_data[num] #print('{:^10}{:^10}{:^10}{:^10}{:^10}{:^10}{:^10}{:^10}{:^10}'.format('地区','累计确诊人数','相较于昨日确诊人数','累计疑似病例','相较于昨日疑似病例','累计治愈人数','相较于昨日治愈人数','累计死亡人数','相较于昨日死亡人数')) for i in data_path: name = i['name'] today = i['today'] total = i['total'] #a = '{:^10}{:^15}{:^15}{:^15}{:^15}{:^15}{:^15}' #print(a.format(name, str(total['confirm']), str(today['confirm']), str(total['confirm']), str(total['suspect']), str(total['heal']), str(total['dead']))) #print(name) shiji="武汉".decode('utf-8') if name==shiji: wuhan='累计确诊人数'.decode('utf-8')+str(total['confirm'])+',相较于昨日确诊人数'.decode('utf-8')+str(today['confirm'])+',累计疑似病例'.decode('utf-8')+str(total['suspect'])+',累计治愈人数'.decode('utf-8')+str(total['heal'])+',累计死亡人数'.decode('utf-8')+str(total['dead']) speak('湖北'.decode('utf-8')) speak(huibei) speak("武汉".decode('utf-8')) speak(wuhan) speak("上海".decode('utf-8')) speak(shanghai) def timer(n): while True: a = int(time.time()) #当前时间 c = datetime.fromtimestamp(a+86400).strftime('%H:%M') #格式转换 '''#定时在早8点,为演示需要每1分钟播报一次 if c>'08:05': l=0 if c=='08:00' and l==0: l=1''' if 1:# print_data_china() print_data_path_china() time.sleep(n) time.sleep(60) timer(60) [/mw_shl_code] |
|
我的问题已经解决了 此外,我想问一个问题。 https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery341001657575837432268_1581070969707&_=1581070969708 以上这个URL是怎么获取? |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶


 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 创客造
创客造
 编辑选择奖
编辑选择奖
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






