|
2899| 0
|
[官方资料] NVIDIA Jetson Nano 2GB 系列文章(49):智能避撞之现场演示 |
|
本帖最后由 jetson小助理 于 2022-4-8 16:06 编辑 避撞功能是 Jetbot 一开始最令人瞩目的功能,因为这是所有小车都必须具备的最基本“自我保护”的能力,而 Jetbot 没有任何距离传感,只凭着一个 CSI 摄像头就能完成这项任务,对很多人来说是一件蛮神奇的事情,Jetbot 是如何识别与周边物体的距离,来决定是继续前进还是得转向? 这里请大家先沉淀一下来思考,人脑是如何学习判断前方的路是可以继续前进?或是有障碍物、坑洞必须转向?请先忘记您的成年人身份,试着模拟刚学会爬行的小婴儿,如何逐步学习并建立这方面的“认知系统”呢?小婴儿对前方的信息来源,有以下三个特点:
在没有其他干预的状况下,小婴儿必定得经过不断地碰撞与摔倒之后,自身防御系统会逐步学习并修正决策机制,这是动物界最原始的学习机制。小婴儿在这个过程所接收的信息,就是没有距离、没有物件类别的最基本“图像”而已。 到目前为止,Jetbot 的运作逻辑是最接近人类行进思维的一套智能无人车,因为我们并不需要去判断与障碍物(或坑洞)之间的确实距离是多近,也不需要分辨前面障碍物是什么东西,就能下达“前进”或“转向”的决策。 当我们安装好 Jetbot 智能车与系统软件之后,接下去就是为每个特定功能添加“深度学习”的智能识别技术进去。例如这个避障的应用就只使用到最基础的“图像识别”能力,将 CSI 镜头的每帧画面识别出“无阻碍(free)”与“有阻碍(blocked)”两种状态,然后发出对应指令去驱动电机执行运动。 任何要添加深度学习的智能识别功能,都必须执行以下三个步骤:
这个避障功能的实验代码在 Jetbot 的 notebooks/collision_avoidance 下,里面有 8 个 .ipynb 文件,包括 1 个 data_collecton.ipynb、3 个 train_modelxxx.ipynb 与 4 个 live_demoxxx.ipynb,分别对应上面所说的三个步骤。不过这些实验代码不需要全都用上,这里以 data_collecton.ipynb、train_model.ipynb 与 live_demo.ipynb 这三个最基本的代码来做说明。 碍于篇幅问题,本文先带着大家运行 live_demo.ipynb 代码,去体验一下 Jetbot 的避障功能,毕竟前面花了这么多时间与精力所组装的系统,先跑起来能获得一些成就感之后,在下一篇文章里再说明比较枯燥的“数据收集与整理”、“模型训练”两大步骤,这样才算完成整个流程。 为了让大家能够先行体验,这里提供原创团队预训练的 best_model.pth 模型的链接,模型的训练方式会在下一篇文章里面说明,这里只管下载到 collision_avoidance 目录下使用就行。文件链接如下:https://drive.google.com/file/d/1UsRax8bR3R-e-0-80KfH2zAt-IyRPtnW/view 由于我们未得到原创团队的授权,不能擅自下载这个存放在 Google 网盘上的文件,再分享给读者下载,请大家能够理解,这需要读者请自行设法下载! 接下来开启 notebooks/collision_avoidance/live_demo.ipynb 工作脚本,逐步执行就能让 Jetbot 小车执行避障的功能。这里面主要分为以下三大部分: 1. 加载训练的模型: 这里关于深度学习的部分,全部使用 PyTorch 这个轻量级的框架,对于不熟悉的读者来说,一开始的两行代码可能就已经会产生不小的困扰,现在就简单地逐行说明:
这是 torchvision 里为 AlexNet 神经网络所预先定义的图像分类功能的结构,其中 classifier[6].out_features 是模型最终的输出数量,也就是分类数量。
注意:每种神经网络的处理方式是不同的,必须根据PyTorch的定义进行调整。 接下去三行代码就是将模型文件加载进来,然后存到 CUDA 设备去,相对直观:
2. 图像格式转换与正规化处理: 这几乎是所有视觉类深度学习应用中不可或缺的步骤,比较繁琐的部分是不同神经网络存在细节上的差异,不过总的来说都脱离不了以下部分: (1) 颜色空间转换:所有神经网络都有自己定义的颜色空间格式,这里的 AlexNet 接受 RGB 数据,而 CSI 摄像头的格式为 BGR,这样就必须进行格式转换。这部分的处理几乎都使用 OpenCV、numpy、PIL 这些强大的图像处理库就可以,下面这行代码就是执行这个功能。
(2) 张量顺序转换:将 HWC 顺序转换成 CHW 顺序,下面指令就是执行顺序调整:
(3) 正规化(normalization)处理:透过减去数据对应维度的统计平均值,消除公共部分以凸显个体之间的差异和特征的一种平稳的分布计算。下面使用到的 [0.485, 0.456, 0.406]、[0.229, 0.224, 0.225] 两组数据,是业界经过公认的经验数据。
以上就是针对读入图像与模型之间对应的一些转换与计算的过程。 3. 创建控制元件并与摄像头进行关联: 这里使用的 traitlets、IPython.display、ipwidgets.wiegets 与 jetbot 的 Camera 库,在前面的文章里都说明过,比较重要的代码如下: (1) blocked_slider:用于显示所获取图像是“blocked”类的几率
(2)speed_slider:用于调整 Jetbot 小车行进速度比
(3)camera_link:将摄像头获取图像与 image 变量进行关联,并执行格式转换,才能在下方“display”指令之后,将摄像头图像动态地在 Jupyter 里显示。
执行这个阶段代码之后,下面应该会出现如下图左方的显示框,试着在镜头前晃动手,看看画面内容是否产生变化?显示框右边与下方分别出现“blocked”与“speed”两个滑块,就是前面代码所建立的小工具。 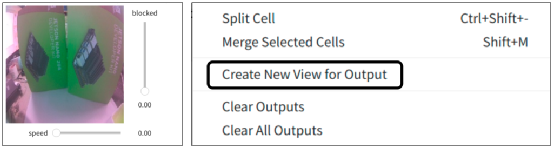 由于后面会使用到这个 “speed” 滑块对 Jetbot 进行速度调整,并且我们也希望能实时观察到摄像头的画面,因此建议用鼠标在画面上点击右键,点选上图右方 “Create New View for Output” 去创建另一个独立输出框,然后进行位置调整如下图,这样就方便后续的操作。 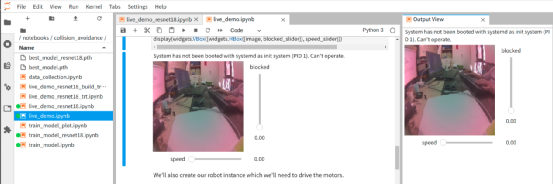 4. 将控制元件与网络模型、机电控制进行结合: 这是整个应用中最核心的整合与计算过程,虽然代码量不多,但信息量却非常大,现在将这部分切割成几个小块来进行说明。 (1) 获取图像进行识别:
(2) 将置信度转换成[0,1]范围的值:
(3)用 prob_blocked 值控制 Jetbot 行进:
执行到这里的时候,正常状况应该如下:
现在可以将 Jetbot 小车放到您安排的执行场地上,在执行下一个步骤之前,建议透过“speed”滑块将速度控制在 0.25 以下,避免启动后造成 Jetbot 小车爆冲。 5. 启动摄像头的动态关联: 这里其实就只有下面这一道指令:
这是由 jetbot 所提供的函数,将 camera.value 与前面定义的 update(change) 进行动态连接上,现在 Jetbot 小车就应该开始行动了,摄像头里的画面也在不停更新,右方“blocked”滑块的值也在不断跳动(更新),现在试着调整“speed”滑块,是不是就能改变行进的速度了! 好了,现在就可以看看您 Jetbot 小车的避障功能执行的如何?如果想停止工作的话,就继续往下执行暂停的指令就可以。 最后需要说明的,假如您的避障功能执行的不是太好,例如无法顺利识别一些障碍物或坑洞的话,通常是因为您的测试场所或者使用的摄像头规格(广角),与原厂提供的模型数据有比较大的差异,甚至场地明暗度也会有影响,如果测试效果不如预期的话,就得自己重头收集数据并重新训练模型,这才是解决问题的根本之道。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






