本帖最后由 云天 于 2023-2-22 22:46 编辑
【项目背景】
让“聋人”看到声音! 世界上有各种各样的残障人士,这些人或不能说话,或听不见声音。聋人,是听力因先天遗传或后天人为因素而受损的残疾人,也叫听力障碍者,简称听障人。根据最近的全国人口普查统计,全中国大约有2700多万听障人,包括弱听、重听、老化聋等。因为各种不方便让其在这个世界上生活极为不方便。 比如有人敲门,水龙头忘关、孩子在卧室里啼哭,可是“听障人”他们听不见。 【项目设计】 利用人工智能,让模型学习各种声音,使用行空板采集声音,通过物联网将相应文字信息发送给 Arduino主板在显示屏上显示并利用灯光提醒,并且利用 micro:bit制作的手表进行文字、灯光加震动提醒,让“听障人”看见、感触到声音。 【项目改进】 上一版本使用波形图,本次学生项目作品使用“语谱图”,使训练出来的模型识别声音的种类和准确度更多更高。
【音频信号】
声音以音频信号的形式表示,音频信号具有频率、带宽、分贝等参数,音频信号一般可表示为振幅和时间的函数。这些声音有多种格式,因此计算机可以对其进行读取和分析。例如:mp3 格式、WMA (Windows Media Audio) 格式、wav (Waveform Audio File) 格式。
【语谱图】
语谱图是二战时期发明的一种语音频谱图,一般是通过处理接收的时域信号得到频谱图。
语谱图是频谱分析视图,如果针对语音数据的话,叫语谱图。语谱图的横坐标是时间,纵坐标是频率,坐标点值为语音数据能量。由于是采用二维平面表达三维信息,所以能量值的大小是通过颜色来表示的,颜色深,表示该点的语音能量越强。
语音的时域分析和频域分析是语音分析的两种重要方法,但是都存在着局限性。时域分析对语音信号的频率特性没有直观的了解,频域特性中又没有语音信号随时间的变化关系。而语谱图综合了时域和频域的优点,明显的显示出了语音频谱随时间的变化情况、语谱图的横轴为时间,纵轴为频率,任意给定频率成分在给定时刻的强弱用颜色深浅来表示。颜色深的,频谱值大,颜色浅的,频谱值小。语谱图上不同的黑白程度形成不同的纹路,称之为声纹,不同讲话者的声纹是不一样的,可用作声纹识别。
【录制音频】
使用pyaudio库这个可以进行录音,生成wav文件。PyAudio 提供了 PortAudio 的 Python 语言版本,这是一个跨平台的音频 I/O 库,使用 PyAudio 你可以在 Python 程序中播放和录制音频。为PoTaTudio提供Python绑定,跨平台音频I/O库。使用PyAudio,您可以轻松地使用Python在各种平台上播放和录制音频。
测试程序,使用pyaudio录制5秒声音文件“output.wav”:
- import pyaudio
- import wave
-
- CHUNK = 1024
- FORMAT = pyaudio.paInt16
- CHANNELS = 2
- RATE = 44100
- RECORD_SECONDS = 5
- WAVE_OUTPUT_FILENAME = "output.wav"
-
- p = pyaudio.PyAudio()
-
- stream = p.open(format=FORMAT,
- channels=CHANNELS,
- rate=RATE,
- input=True,
- frames_per_buffer=CHUNK)
-
- print("* recording")
-
- frames = []
-
- for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
- data = stream.read(CHUNK)
- frames.append(data)
-
- print("* done recording")
-
- stream.stop_stream()
- stream.close()
- p.terminate()
-
- wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
- wf.setnchannels(CHANNELS)
- wf.setsampwidth(p.get_sample_size(FORMAT))
- wf.setframerate(RATE)
- wf.writeframes(b''.join(frames))
- wf.close()
-
【批量生成语谱图】


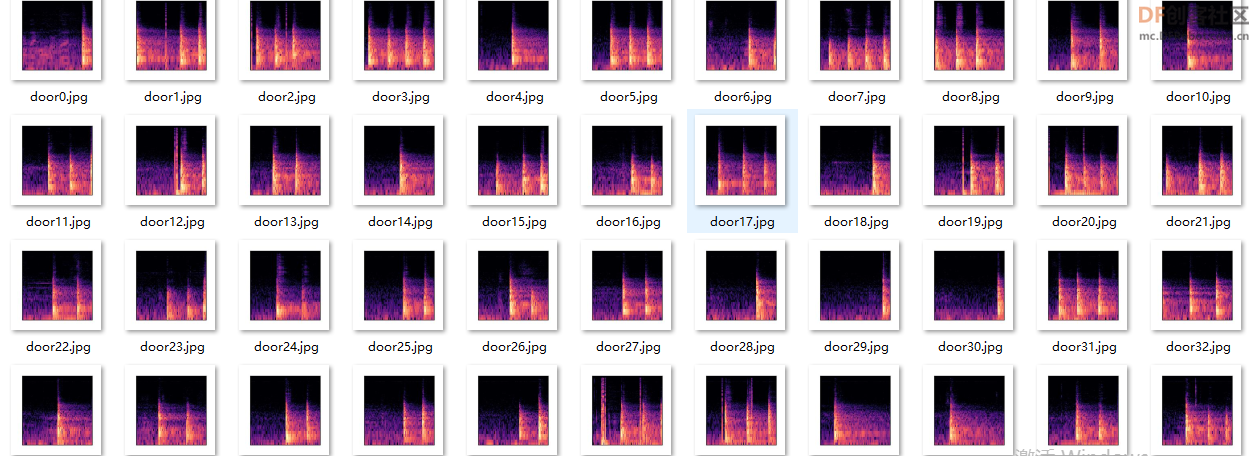

使用Librosa库批量生成各类声音的语谱图,如敲门声、水龙头流水声、婴儿啼哭声、警报声等。
Librosa是一个用于音频、音乐分析、处理的python工具包,一些常见的时频处理、特征提取、绘制声音图形等功能应有尽有,功能十分强大。
Librosa语音频谱图
- librosa.display.specshow(data, x_axis=None, y_axis=None, sr=22050, hop_length=512)
参数:
data:要显示的矩阵
sr :采样率
hop_length :帧移
x_axis 、y_axis :x和y轴的范围
频率类型
‘linear’,‘fft’,‘hz’:频率范围由 FFT 窗口和采样率确定
‘log’:频谱以对数刻度显示
‘mel’:频率由mel标度决定
时间类型
time:标记以毫秒,秒,分钟或小时显示。值以秒为单位绘制。
s:标记显示为秒。
ms:标记以毫秒为单位显示。
所有频率类型均以Hz为单位绘制
- #加载模块:
-
- import pyaudio
- import numpy as np
- import matplotlib.pyplot as plt
- from tqdm import tqdm
- from matplotlib.backends.backend_agg import FigureCanvasAgg as FigureCanvas
- import librosa.display
- import pandas as pd
- import librosa
-
- def record_audio(record_second):
- global wave
- CHUNK = 1024
- FORMAT = pyaudio.paInt16
- CHANNELS = 1
- RATE = 44100
-
- p = pyaudio.PyAudio()
- stream = p.open(format=FORMAT,
- channels=CHANNELS,
- rate=RATE,
- input=True,
- frames_per_buffer=CHUNK)
- audio_data = []
- print("* recording")
- for i in tqdm(range(0, int(RATE / CHUNK * record_second))):
- data = stream.read(CHUNK)
- audio_data.append(data)
- audio_samples = librosa.core.samples_to_frames(
- np.frombuffer(b''.join(audio_data), dtype=np.int16),
- CHANNELS,
- hop_length=CHUNK
- )
- wave = audio_samples[5500:5500+int(1 * RATE)]/2**16
-
- print("* done recording")
- stream.stop_stream()
- stream.close()
- p.terminate()
-
- for i in range(50):
- #录制音频
- record_audio(record_second=2)
- #加载音频:
-
- window_size = 1024
- window = np.hanning(window_size)
- stft = librosa.core.spectrum.stft(wave, n_fft=window_size, hop_length=512, window=window)
- out = 2 * np.abs(stft) / np.sum(window)
- # For plotting headlessly
- fig = plt.figure(figsize=(2.24, 2.24))
- ax = fig.add_subplot(111)
- ax.axes.xaxis.set_visible(False)
- ax.axes.yaxis.set_visible(False)[indent]#生成语音频谱图
- p = librosa.display.specshow(librosa.amplitude_to_db(out, ref=np.max), ax=ax, y_axis='log', x_axis='time')
- fig.savefig('save'+str(i)+'.jpg')
-
注:需在行空板程序所在目录建立相应文件夹,如“door”,生成图像后,拷贝到电脑,使用ML训练模型。
【硬件制作过程】 一、行空板主控 按钮接行空板引脚21(用于关闭提醒),LED灯接引脚22(用于亮灯提醒)。
将震动马达接“掌控宝”的M2接口,并粘在表带上。当掌控板收到信息后,启动震动马达开始震动,提醒“听障人”查看屏幕提示信息。
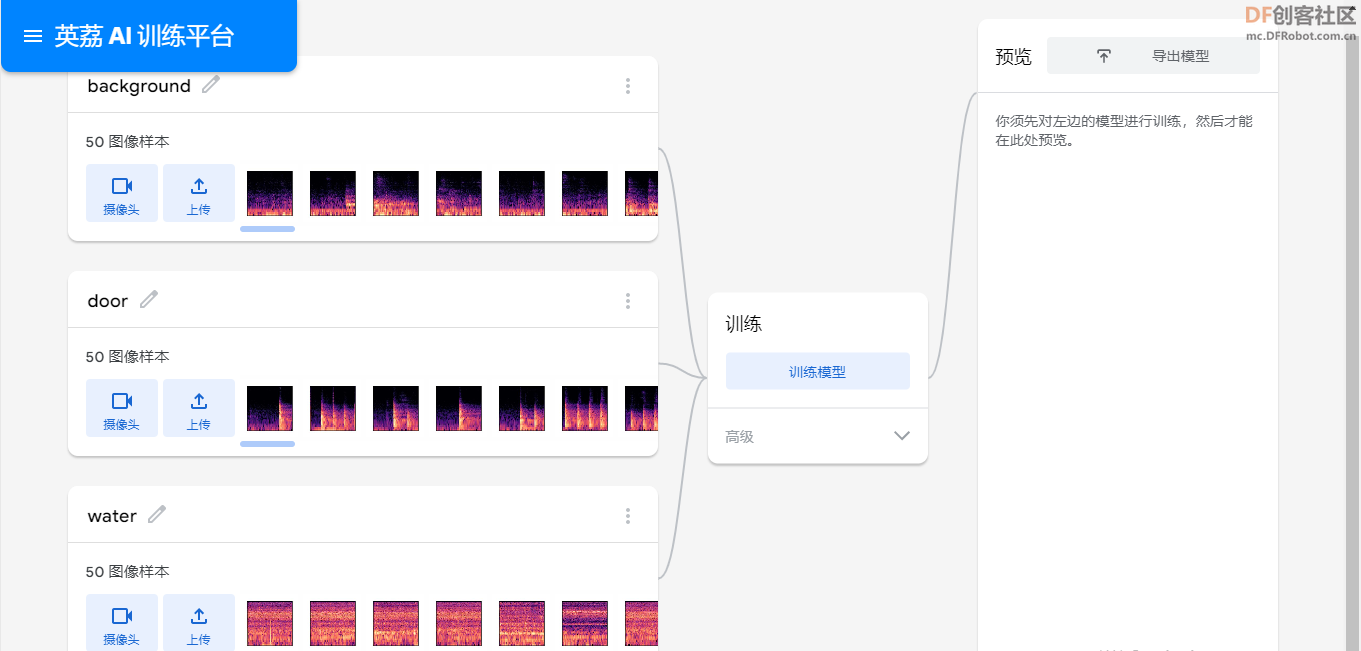
【训练模型】
将图片上传到“英艻AI训练平台”进行模型训练。类型有[size=18.6667px]“background”[size=18.6667px]、“door”、“water”。
【电脑推理测试】
下载模型,放到程序相应目录下。 - #加载模块:
-
- import pyaudio
- #from unihiker import Audio
- import numpy as np
- import matplotlib.pyplot as plt
- from PIL import Image, ImageOps #Install pillow instead of PIL
- from tqdm import tqdm
- from matplotlib.backends.backend_agg import FigureCanvasAgg as FigureCanvas
- import librosa.display
- import pandas as pd
- import librosa
- from keras.models import load_model
-
- # 禁用科学符号
- np.set_printoptions(suppress=True)
- #内容.config(text="加载模型")
- # 加载模型
- model = load_model('keras_model.h5', compile=False)
- # 加载标签
- class_names = ['background','jianpan','desktop']
-
- #创建正确形状的数组以输入keras模型
- #可以放入阵列的图像的“长度”或数量为
- #由形状元组中的第一位置(在这种情况下为1)确定。
-
- data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32)
- #录制声音函数
- def record_audio(record_second):
- global wave
- CHUNK = 1024
- FORMAT = pyaudio.paInt16
- CHANNELS = 1
- RATE = 44100
-
- p = pyaudio.PyAudio()
- stream = p.open(format=FORMAT,
- channels=CHANNELS,
- rate=RATE,
- input=True,
- frames_per_buffer=CHUNK)
- audio_data = []
- print("* recording")
- for i in tqdm(range(0, int(RATE / CHUNK * record_second))):
- data = stream.read(CHUNK)
- audio_data.append(data)
- audio_samples = librosa.core.samples_to_frames(
- np.frombuffer(b''.join(audio_data), dtype=np.int16),
- CHANNELS,
- hop_length=CHUNK
- )
- wave = audio_samples[5500:5500+int(1 * RATE)]/2**16
- print("* done recording")
- stream.stop_stream()
- stream.close()
- p.terminate()
-
-
-
- while(True):
-
- [/indent][indent] #录制音频
- record_audio(record_second=2)
- #加载音频保存语谱图
- window_size = 1024
- window = np.hanning(window_size)
- stft = librosa.core.spectrum.stft(wave, n_fft=window_size, hop_length=512, window=window)
- out = 2 * np.abs(stft) / np.sum(window)
- #绘制
- fig = plt.figure(figsize=(2.24, 2.24))
- ax = fig.add_subplot(111)[/indent][indent] #不显示横纵坐标轴
- ax.axes.xaxis.set_visible(False)
- ax.axes.yaxis.set_visible(False)[/indent] #生成语音频谱图保存
- p = librosa.display.specshow(librosa.amplitude_to_db(out, ref=np.max), ax=ax, y_axis='log', x_axis='time')
- fig.savefig('wave.jpg')
- #打开语音频谱图
- image = Image.open('wave.jpg').convert('RGB')
- #将图像转换为numpy数组
- image_array = np.asarray(image)
- # 图像规格化
- normalized_image_array = (image_array.astype(np.float32) / 127.0) - 1
- #将图像加载到数组中
- data[0] = normalized_image_array
- # 运行推断
- prediction = model.predict(data)
-
- index = np.argmax(prediction)
- #获取标签
- class_name = class_names[index]
- #获取置信度
- confidence_score = prediction[0][index]
- print('Class:', class_name)
- print('Confidence score:', confidence_score)
-
【行空板推理】
下载模型,放到行空板程序相应目录。 利用行空板板载麦克风采集声音,利用matplotlib变换成图片,使用keras加载训练好的模型“keras_model.h5”,进行预测出声音类型。点亮LED灯并通过物联网发送相关信息指令。 -
-
- #加载模块:
-
- from unihiker import GUI
- u_gui=GUI()
- 显示=u_gui.draw_text(text="智能提示器",x=0,y=100,font_size=35, color="#0000FF")
- 内容=u_gui.draw_text(text="加载库",x=20,y=180,font_size=35, color="#0000FF")
- from pinpong.extension.unihiker import *
- from pinpong.board import Board,Pin,NeoPixel
-
- import pyaudio
- #from unihiker import Audio
- import numpy as np
- import matplotlib.pyplot as plt
- from PIL import Image, ImageOps #Install pillow instead of PIL
- from tqdm import tqdm
- from matplotlib.backends.backend_agg import FigureCanvasAgg as FigureCanvas
- import librosa.display
- import pandas as pd
- import librosa
- from keras.models import load_model
-
- import siot
-
- Board().begin()
- p_p22_out=Pin(Pin.P22, Pin.OUT)
- p_p21_in=Pin(Pin.P21, Pin.IN)
- np1 = NeoPixel(p_p22_out,1)
- np1[0] = (0,0,0)
-
- # 禁用科学符号
- np.set_printoptions(suppress=True)
- #内容.config(text="加载模型")
- # 加载模型
- model = load_model('keras_model.h5', compile=False)
- # 加载标签
- class_names = ['background','door','water']
-
- #创建正确形状的数组以输入keras模型
- #可以放入阵列的图像的“长度”或数量为
- #由形状元组中的第一位置(在这种情况下为1)确定。
-
- data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32)
-
- 内容.config(text="连物联网")
-
- siot.init(client_id="",server="iot.dfrobot.com.cn",port=1883,user="X8jykxFnR",password="u8jskbFngz")
-
- siot.connect()
-
- siot.loop()
-
-
- def record_audio(record_second):
- global wave
- CHUNK = 1024
- FORMAT = pyaudio.paInt16
- CHANNELS = 1
- RATE = 44100
-
- p = pyaudio.PyAudio()
- stream = p.open(format=FORMAT,
- channels=CHANNELS,
- rate=RATE,
- input=True,
- frames_per_buffer=CHUNK)
- audio_data = []
- print("* recording")
- for i in tqdm(range(0, int(RATE / CHUNK * record_second))):
- data = stream.read(CHUNK)
- audio_data.append(data)
- audio_samples = librosa.core.samples_to_frames(
- np.frombuffer(b''.join(audio_data), dtype=np.int16),
- CHANNELS,
- hop_length=CHUNK
- )
- wave = audio_samples[5500:5500+int(1 * RATE)]/2**16
- print("* done recording")
- stream.stop_stream()
- stream.close()
- p.terminate()
-
-
-
- while(True):
- if (p_p21_in.read_digital()==True):
- siot.publish(topic="1DXAmWJ4g", data="S")
- np1[0] = (0,0,0)
- else:
-
- #录制音频
- 内容.config(text="录音中……")
- record_audio(record_second=2)
- 内容.config(text="识别中……")
- #加载音频:
- window_size = 1024
- window = np.hanning(window_size)
- stft = librosa.core.spectrum.stft(wave, n_fft=window_size, hop_length=512, window=window)
- out = 2 * np.abs(stft) / np.sum(window)
- # 绘制
- fig = plt.figure(figsize=(2.24, 2.24))
- ax = fig.add_subplot(111)
- ax.axes.xaxis.set_visible(False)
- ax.axes.yaxis.set_visible(False)
- p = librosa.display.specshow(librosa.amplitude_to_db(out, ref=np.max), ax=ax, y_axis='log', x_axis='time')
- fig.savefig('wave.jpg')
-
- image = Image.open('wave.jpg').convert('RGB')
-
- #将图像转换为numpy数组
- image_array = np.asarray(image)
-
- # 规格化图像
- normalized_image_array = (image_array.astype(np.float32) / 127.0) - 1
- # 将图像加载到数组中
- data[0] = normalized_image_array
- # 运行推断
- prediction = model.predict(data)
- index = np.argmax(prediction)
- class_name = class_names[index]
-
- confidence_score = prediction[0][index]
-
- if class_name=='background':
- siot.publish(topic="1DXAmWJ4g", data="B")
- np1[0] = (0,0,0)
- 内容.config(text='背景音')
- elif class_name=='door':
- siot.publish(topic="1DXAmWJ4g", data="D")
- np1[0] = (0,255,0)
- 内容.config(text='敲门')
- elif class_name=='water':
- siot.publish(topic="1DXAmWJ4g", data="W")
- np1[0] = (0,0,255)
- 内容.config(text='流水')
- print('Class:', class_name)
-
- print('Confidence score:', confidence_score)
-
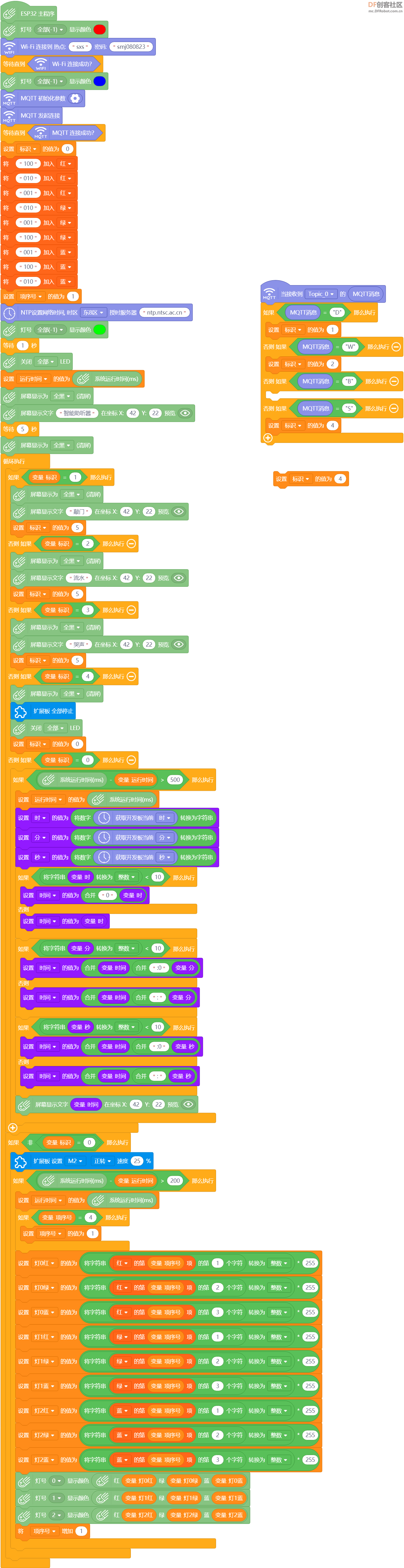
【掌控板手表程序】 通过物联网接收行空板传来的指令,屏幕显示相应信息,板载LED灯循环闪烁,并驱动马达震动。
|











 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶





 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 创客造
创客造
 编辑选择奖
编辑选择奖
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






