|
2771| 0
|
[官方资料] NVIDIA Jetson Nano 2GB 系列文章(39):结合IoT信息传输 |

前一篇文章特别介绍 DeepStream 的 nvdsanalytics 视频分析插件,能对视频中特定的多边形封闭区域或是某条界线,在“某时间”的动态分析与“某时段”的累积统计数据,甚至包括行进方向的物件统计等等,下图就是 nvdsanalytics 插件范例的执行结果,图左显示了非常多的动态信息,十分强大。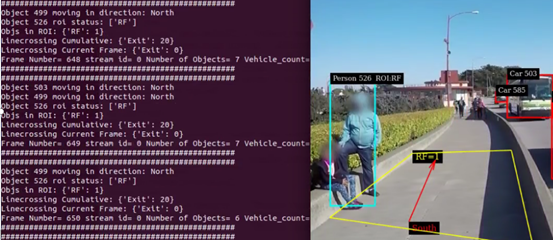 既然 nvdsanalytics 插件已经帮我们将视频内容转化成字符信息,接下去的重点就是将这些信息上传到一个数据汇总的服务器,这样就能完成一个 IoT 应用的完整循环。为了实现这样的目的,DeepStream 从 3.0 就提供 nvmsgconv 与 nvmsgbroker 这两个插件,分工合作来完成这项信息传递的任务。 本文的范例是 deepstream-python-apps 下面的 deepstream-test4,里面的插件流与前面的几个范例的流程大致相同,因此这里不花时间在插件流部分多做说明,除了最后面的“tee”插件对信息做分流的处理,其余部分都是前面范例中已经详细讲解过的内容。简单整理一下本范例的插件流顺序给大家参考一下,如下所示: tee 这个 Gstreamer 开源插件将信息交给 nvmsgconv / nvmsgbroker 这两个插件去处理与传递,另一个分流则让数据能在本机上的显示器上输出视频画面。 本范例最重要的任务,在于让大家进一步了解并熟悉 nvmsgconv 与 nvmsgbroker 的内容与用法,并没有执行 nvdsanalytics 的视频分析功能,所有重点都聚焦在“信息传送”的插件本身,与前后台设备的部分。 现在就开始实验的内容部分。
这个插件的功能就是将前面检测到并存放在缓冲区的信息抽取出来,这是透过插件输入端的 Gst buffer、NvDsBatchMeta 与 NvDsEventMsgMeta 带进来(如下图),定义一个用户元数据(user_event_meta,在代码第 301 行),将 base_meta.meta_type 设为 NVDS_EVENT_MSG_META 数据类型,生成的有效负载(NvDsPayload)再以 NVDS_PAYLOAD_META 类型据附加回输入缓冲区,然后再用 pyds.user_copyfunc 将数据复制过来就可以。 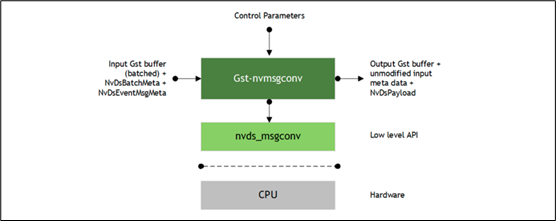 在 DeepStream 5.1 里的 nvmsgconv 插件有两种工作模式:
这个插件的任务,就是将 nvmsgconv 传送过来的有效负载数据,透过所支持的转接器(adapter)协议上传到指定的接收器去。目前 DeepStream 5.1 支持 Kafka、AMQP 与 AzureIoT 三种转接协议。 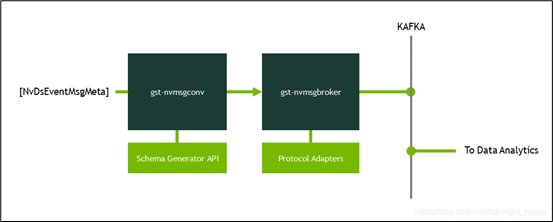 本范例使用 Kafka 这个协议来做示范,至于另外两种协议,在范例目录下也提供参考的配置文件,可以之间进行修改就行。
整个 deepstream-test4.py 代码结构与 deepstream-test1.py 差不多,所以代码内容就不花时间讲解,如果有不了解的请参考前面文章的内容。 这个范例有个比较特别的部分,就是需要有“信息产生设备”与“信息接收设备”两部分,当然这两个设备也可以使用同一台来扮演。 为了便于操作,接下来的演示我们将二者都放在同一台 Jetson Nano 2GB 上执行,但逻辑上将它视为两个设备:
由于 Kafka 需要 ZooKeeper 来进行管理,因此在启动 Kafka 服务之前,必须先启动 ZooKeeper 作为后台管理,还好 Kafka 已经提供可执行的脚本与配置,就不需要额外再下载与编译 ZooKeeper。 在启动 ZooKeeper 之前,还得先为其建立相关的 Java 数据库,因此这里有几个步骤需要执行:
因为这里使用 Jetson Nano 2GB 作为 Kafka 接收器,因此后面的<IP:端口>设置为“localhost:9092”,下面指令的粗体部分内容,必须与后面发送端的“--conn-str=<IP;PORT;TOPIC>内容一致。
现在 Kafka 接收器的三个服务都已经处于如下图的接收信息状态: 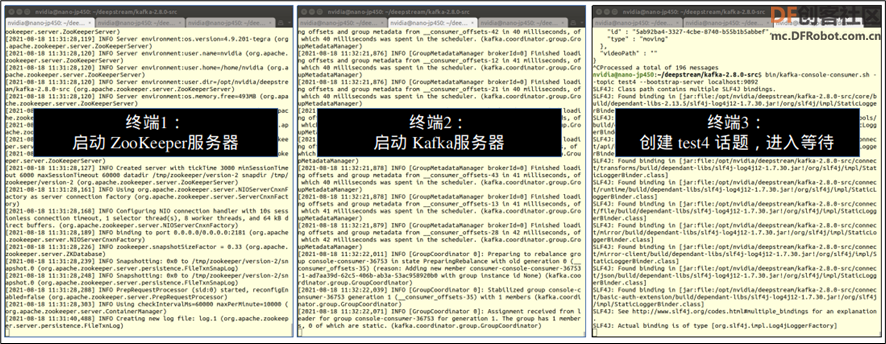 2. 信息发送端:deepstream-test4 范例执行设备
注意这里--conn-str=后面的参数,必须与接收端的设定值一致。最后面的-s 参数是选择使用完整信息模式还算简易信息模式。 如果出现“unable to connect to broker library”错误信息,表示没找到 kafka Server,请检查接收端三个服务的状态。 如果一切都调试好,执行后会出现下面状态,左边是用 deepstream-test4.py 执行推理计算,将信息传送到右边的接收器去进行显示: 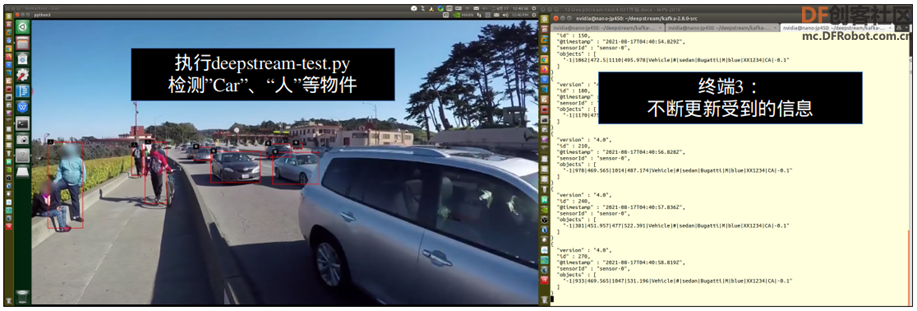 用-s 选择传送不同格式的信息,“0”表示使用完整格式(如下图左),“1”则选择简化格式(如下图右),这样就完成 IoT 信息传送的应用了。 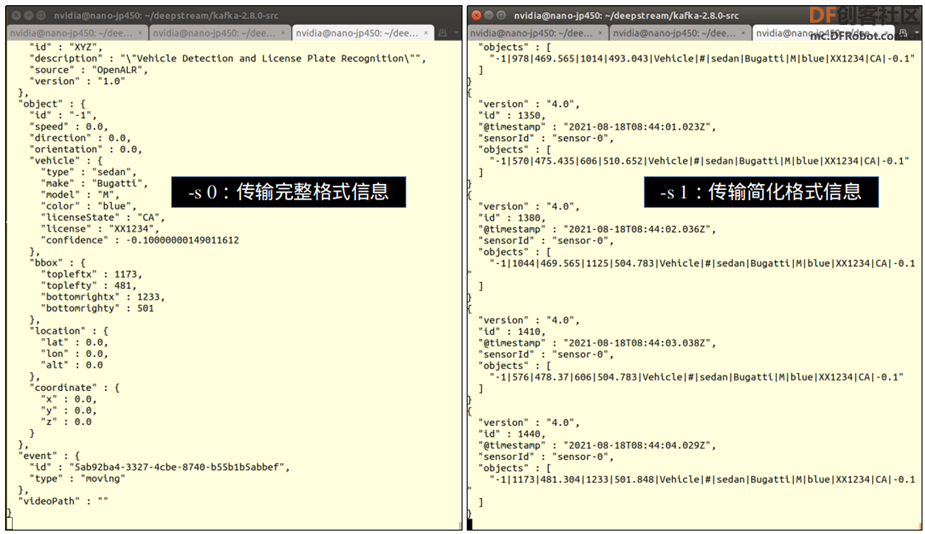 在 deepstream-test4.py 只调用基础的 2 类别物件检测器,我们可以自行尝试将 deepstream-nvdsanalytics.py 与这个范例相结合,就能开发出一个实用性非常高的“AI-IOT 视频分析”应用。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






