【项目背景】 随着社会的快速发展,城市环境日益复杂,对于视障人士来说,独立出行和寻找公共设施如卫生间等变得越来越困难。尽管许多城市已经在公共场所设置了无障碍设施,但是对于视障人士而言,如何快速准确地找到并识别这些设施仍然是一个挑战。此外,隐私保护也是现代社会的一个重要议题,确保在提供帮助的同时不侵犯他人的隐私权是技术发展必须考虑的因素。 本项目旨在利用人工智能技术,通过行空板结合摄像头和蓝牙设备,开发一款专为视障人士设计的智能识别厕辅助设备。该设备能够在保护个人隐私的前提下,帮助视障人士通过图像识别和文字识别技术快速定位卫生间,并区分男女卫生间,从而提高他们的出行便利性和生活质量。
【项目特点】
隐私保护:所有图像识别处理均在本地完成,不涉及图像数据的存储和传输,确保了公共场所中其他人的隐私安全。
实时语音反馈:通过蓝牙连接到耳机,设备能够实时向视障人士提供语音反馈,告知他们当前识别到的设施信息。
多模态识别:结合图像识别和文字识别技术,提高识别的准确性和鲁棒性。
易于使用:设备操作简单,视障人士可以轻松上手,无需额外的学习成本。
【技术实现】
1.硬件准备与配置
选择并准备主控板行空板,确保其具备USB接口以连接摄像头。
准备一个USB摄像头用于捕捉图像。
准备蓝牙耳机或音箱,用于接收行空板传输的语音提示。
为展示需要,使用蓝牙音箱代替蓝牙耳机
测试用卫生间门牌标识
利用讯飞绘画大师,绘制项目Logo
2.软件开发环境搭建
安装Python编程语言环境,因为行空板支持Python作为开发语言。
安装必要的库,包括但不限于OpenCV(图像处理)、pyttsx3(文本到语音转换)、XEdu.hub(模型推理库)等。
3.蓝牙连接模块开发
利用Python的subprocess模块,调用系统命令来控制蓝牙设备,实现与蓝牙耳机的配对和连接。
开发connect_bluetooth函数,用于搜索并连接指定MAC地址的蓝牙设备。
开发is_connected函数,用于检查蓝牙设备是否已经连接。
4.图像采集模块开发
使用OpenCV库,通过摄像头采集实时图像数据。
配置摄像头参数,如分辨率、帧率等,以适应不同的使用环境。
5.图像处理与识别模块开发
利用XEdu.hub库加载目标检测和文本识别模型。
开发图像预处理功能,如调整亮度、对比度等,以提高识别准确率。
实现实时图像识别功能,通过目标检测模型识别图像中的物体,并统计特定物体的出现次数。
6.文本识别与语音提示模块开发 使用XEdu.hub库加载OCR模型,对图像中的文字进行识别。
开发valve_getkey函数,用于从识别结果中提取关键信息。
开发语音提示功能,将识别结果转换为语音,并通过蓝牙设备播放给用户。
7.交互逻辑开发 开发主循环,实现持续的图像采集、处理和识别。
根据识别结果,如检测到卫生间标识或文字,触发相应的语音提示。
如果未检测到卫生间,通过目标检测模型识别路人,并提供语音提示,建议用户询问路人。
8.隐私保护措施
确保所有图像处理和识别仅在本地进行,不上传至云端或进行存储。
设计合理的数据处理流程,避免在公共场合捕捉和处理敏感信息。
【程序编写】
1.提示语音生成
2.文字识别
3.目标检测
【完整程序】
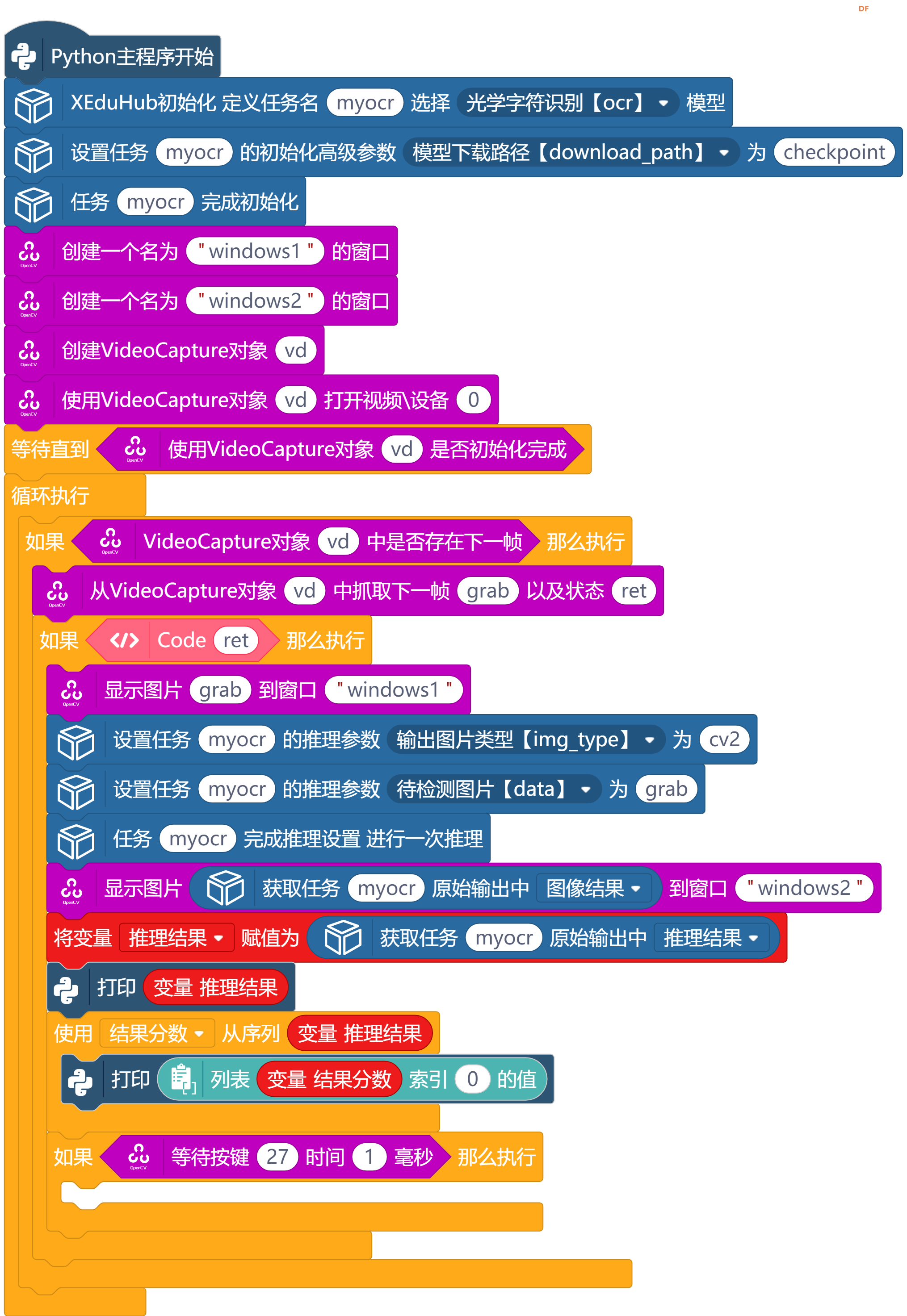
1、图形化程序

2.代码程序python
- # -*- coding: UTF-8 -*-
-
- # MindPlus
- # Python
- import re
- import cv2
- import sys
- import time
- import pyttsx3
-
- from unihiker import Audio
- from pinpong.board import Board,Pin
- from pinpong.extension.unihiker import *
- from XEdu.hub import Workflow as wf
- import os
-
- def valve_getkey(result_val,result_key):
- val_len = len(result_val)
- if val_len<1:
- raise ValueError("Error:推理结果为空,请检查传入的图像或推理参数是否有问题。")
- if val_len==1 and result_key==1:
- raise ValueError("Error:推理结果中无图像,请检查推理参数中img_type项。")
- try:
- return result_val[result_key]
- except Exception as e:
- raise ValueError(f"Error: 从推理原始结果中取值错误。result_val:{result_val}, result_key:{result_key}。\nException:{e} ")
-
- def format_valve_output(task):
- try:
- output_result = ""
- output_result = task.format_output(lang="zh")
- return output_result
- except AttributeError:
- return "AttributeError: 请检查输入数据是否正确"
-
- u_audio = Audio()
- para_目标 = {}
- para_myocr = {}
- Board().begin()
- p_p24_in=Pin(Pin.P24, Pin.IN)
- engine = pyttsx3.init()
- print("智能识厕设备开始启动")
- u_audio.play("wav/speech1.wav")
- LeiBie = {"person": "人", "bicycle": "自行车", "car": "汽车", "motorbike": "摩托车", "aeroplane": "飞机", "bus": "公共汽车", "train": "火车", "truck": "卡车", "boat": "小船", "traffic light": "交通灯", "fire hydrant": "消防栓", "stop sign": "停车标志", "parking meter": "停车计时器", "bench": "长凳", "bird": "鸟", "cat": "猫", "dog": "狗", "horse": "马", "sheep": "羊", "cow": "牛", "elephant": "大象", "bear": "熊", "zebra": "斑马", "giraffe": "长颈鹿", "backpack": "背包", "umbrella": "伞", "handbag": "手提包", "tie": "领带", "suitcase": "手提箱", "frisbee": "飞盘", "skis": "滑雪板", "snowboard": "滑雪板", "sports ball": "运动球", "kite": "风筝", "baseball bat": "棒球棒", "baseball glove": "棒球手套", "skateboard": "滑板", "surfboard": "冲浪板", "tennis racket": "网球拍", "bottle": "瓶子", "wine glass": "葡萄酒杯", "cup": "杯子", "fork": "叉子", "knife": "刀", "spoon": "勺子", "bowl": "碗", "banana": "香蕉", "apple": "苹果", "sandwich": "三明治", "orange": "橙子", "broccoli": "西兰花", "carrot": "胡萝卜", "hot dog": "热狗", "pizza": "披萨", "donut": "甜甜圈", "cake": "蛋糕", "chair": "椅子", "sofa": "沙发", "pottedplant": "盆栽植物", "bed": "床", "diningtable": "餐桌", "toilet": "厕所", "tvmonitor": "电视监视器", "laptop": "笔记本电脑", "mouse": "鼠标", "remote": "遥控器", "keyboard": "键盘", "cell phone": "手机", "microwave": "微波炉", "oven": "烤箱", "toaster": "烤面包机", "sink": "洗涤槽", "refrigerator": "冰箱", "book": "书", "clock": "时钟", "vase": "花瓶", "scissors": "剪刀", "teddy bear": "泰迪熊", "hair drier": "吹风机", "toothbrush": "牙刷"}
- ShiJian = time.time()
- JiLuLeiXing = { "person": 0, "bicycle": 0, "car": 0, "motorbike": 0, "aeroplane": 0, "bus": 0, "train": 0, "truck": 0, "boat": 0, "traffic light": 0, "fire hydrant": 0, "stop sign": 0, "parking meter": 0, "bench": 0, "bird": 0, "cat": 0, "dog": 0, "horse": 0, "sheep": 0, "cow": 0, "elephant": 0, "bear": 0, "zebra": 0, "giraffe": 0, "backpack": 0, "umbrella": 0, "handbag": 0, "tie": 0, "suitcase": 0, "frisbee": 0, "skis": 0, "snowboard": 0, "sports ball": 0, "kite": 0, "baseball bat": 0, "baseball glove": 0, "skateboard": 0, "surfboard": 0, "tennis racket": 0, "bottle": 0, "wine glass": 0, "cup": 0, "fork": 0, "knife": 0, "spoon": 0, "bowl": 0, "banana": 0, "apple": 0, "sandwich": 0, "orange": 0, "broccoli": 0, "carrot": 0, "hot dog": 0, "pizza": 0, "donut": 0, "cake": 0, "chair": 0, "sofa": 0, "pottedplant": 0, "bed": 0, "diningtable": 0, "toilet": 0, "tvmonitor": 0, "laptop": 0, "mouse": 0, "remote": 0, "keyboard": 0, "cell phone": 0, "microwave": 0, "oven": 0, "toaster": 0, "sink": 0, "refrigerator": 0, "book": 0, "clock": 0, "vase": 0, "scissors": 0, "teddy bear": 0, "hair drier": 0, "toothbrush": 0}
- LeiXingLieBiao = []
- print("开始加载目标检测模型")
- u_audio.play("wav/speech2.wav")
- init_para_目标 = {"task":"det_coco"}
- init_para_目标["download_path"] = r"checkpoint"
- 目标 = wf(**init_para_目标)
- print("目标检测模型加载成功")
- u_audio.play("wav/speech3.wav")
- print("开始加载文本识别模型")
- u_audio.play("wav/speech4.wav")
- init_para_myocr = {"task":"ocr"}
- init_para_myocr["download_path"] = r"checkpoint"
- myocr = wf(**init_para_myocr)
- print("加载文本识别模型成功")
- u_audio.play("wav/speech5.wav")
- cv2.namedWindow("windows1", cv2.WINDOW_NORMAL)
- cv2.resizeWindow("windows1", 240, 320)
- cv2.setWindowProperty("windows1", cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
- vd = cv2.VideoCapture()
- vd.set(cv2.CAP_PROP_BUFFERSIZE, 1)
- vd.open(0)
- while not (vd.isOpened()):
- pass
- print("启动摄像头成功")
- u_audio.play("wav/speech6.wav")
-
- while True:
- if vd.grab():
- ret, grab = vd.read()
- if ret:
- cv2.imshow("windows1", grab)
- if (p_p24_in.read_digital()==True):
- print("开始识别")
- u_audio.play("wav/speech7.wav")
- para_myocr["img_type"] = "cv2"
- para_myocr["data"] = grab
-
- if 'myocr' in globals() or 'myocr' in locals():
- rea_result_myocr = myocr.inference(**para_myocr)
- else:
- print("init",'myocr')
- myocr = wf(**init_para_myocr)
- rea_result_myocr = myocr.inference(**para_myocr)
-
- cv2.imshow("windows1", valve_getkey(rea_result_myocr,1))
- TuiLiJieGuo = valve_getkey(rea_result_myocr,0)
- JiShu = 0
- JieGuo = ""
- for JieGuoFenShu in TuiLiJieGuo:
- ShiBieZhi = (JieGuoFenShu[0])
- if ((ShiBieZhi.find("男")!=-1) and (ShiBieZhi.find("女")!=-1)):
- JiShu = 3
- elif ((ShiBieZhi.find("男")!=-1) and (not (ShiBieZhi.find("女")!=-1))):
- JiShu = (JiShu + 1)
- JieGuo = "男卫生间"
- elif ((not (ShiBieZhi.find("男")!=-1)) and (ShiBieZhi.find("女")!=-1)):
- JiShu = (JiShu + 1)
- JieGuo = "女卫生间"
- elif ((ShiBieZhi.find("卫生间")!=-1) or ((ShiBieZhi.find("洗手间")!=-1) or (ShiBieZhi.find("厕所")!=-1))):
- JiShu = 4
- if (JiShu == 1):
- print(JieGuo)
- if (JieGuo.find("男")!=-1):
- u_audio.play("wav/speech8.wav")
- else:
- u_audio.play("wav/speech9.wav")
- elif (JiShu > 1):
- print("卫生间")
- JieGuo = "卫生间"
- u_audio.play("wav/speech10.wav")
- elif (JiShu == 0):
- while not (((time.time() - ShiJian) > 1)):
- para_目标["img_type"] = "cv2"
- para_目标["data"] = grab
-
- if '目标' in globals() or '目标' in locals():
- rea_result_目标 = 目标.inference(**para_目标)
- else:
- print("init",'目标')
- 目标 = wf(**init_para_目标)
- rea_result_目标 = 目标.inference(**para_目标)
-
- cv2.imshow("windows1", valve_getkey(rea_result_目标,1))
- output_result_目标 = format_valve_output(目标)
- TuiLiJieGuo = output_result_目标
- XuHao = 0
- for JieGuoFenShu in output_result_目标["分数"]:
- if (JieGuoFenShu > 0.7):
- print(XuHao)
- LeiBieJieGuo = (output_result_目标["类别"][XuHao])
- XuHao = (XuHao + 1)
- if (not LeiBieJieGuo in LeiXingLieBiao):
- LeiXingLieBiao.insert(0,LeiBieJieGuo)
- JiLuLeiXing[LeiBieJieGuo]=((JiLuLeiXing[LeiBieJieGuo]) + 1)
- for JianYanLeiXing in LeiXingLieBiao:
- if ((JiLuLeiXing[JianYanLeiXing]) > 5):
- print((LeiBie[JianYanLeiXing]))
- print((JiLuLeiXing[JianYanLeiXing]))
- engine.say((str("面前有") + str((str((LeiBie[JianYanLeiXing])) + str("出现")))))
- engine.runAndWait()
- JiLuLeiXing = { "person": 0, "bicycle": 0, "car": 0, "motorbike": 0, "aeroplane": 0, "bus": 0, "train": 0, "truck": 0, "boat": 0, "traffic light": 0, "fire hydrant": 0, "stop sign": 0, "parking meter": 0, "bench": 0, "bird": 0, "cat": 0, "dog": 0, "horse": 0, "sheep": 0, "cow": 0, "elephant": 0, "bear": 0, "zebra": 0, "giraffe": 0, "backpack": 0, "umbrella": 0, "handbag": 0, "tie": 0, "suitcase": 0, "frisbee": 0, "skis": 0, "snowboard": 0, "sports ball": 0, "kite": 0, "baseball bat": 0, "baseball glove": 0, "skateboard": 0, "surfboard": 0, "tennis racket": 0, "bottle": 0, "wine glass": 0, "cup": 0, "fork": 0, "knife": 0, "spoon": 0, "bowl": 0, "banana": 0, "apple": 0, "sandwich": 0, "orange": 0, "broccoli": 0, "carrot": 0, "hot dog": 0, "pizza": 0, "donut": 0, "cake": 0, "chair": 0, "sofa": 0, "pottedplant": 0, "bed": 0, "diningtable": 0, "toilet": 0, "tvmonitor": 0, "laptop": 0, "mouse": 0, "remote": 0, "keyboard": 0, "cell phone": 0, "microwave": 0, "oven": 0, "toaster": 0, "sink": 0, "refrigerator": 0, "book": 0, "clock": 0, "vase": 0, "scissors": 0, "teddy bear": 0, "hair drier": 0, "toothbrush": 0}
- LeiXingLieBiao = []
- ShiJian = time.time()
- if cv2.waitKey(1) & 0xff== 27:
- pass
-
以上代码是一个基于Python的智能识别系统,旨在帮助视障人士通过语音提示找到卫生间。系统使用MindPlus框架,结合行空板和USB摄像头,通过OpenCV库捕获实时图像。它利用XEdu.hub库加载并运行目标检测和文本识别模型,以识别图像中的物体和文字。当用户按下与行空板连接的按钮时,系统开始工作,首先尝试识别图像中的文字,判断是否为男卫生间或女卫生间的标志。如果没有直接识别到卫生间标志,系统会通过目标检测模型分析图像,识别出图像中的常见物体,并统计特定物体的出现次数。如果某物体出现次数超过阈值,系统会通过连接的蓝牙音箱,使用pyttsx3库将物体名称转换为语音,提示用户。整个过程中,系统还考虑了隐私保护,确保所有图像处理都在本地完成,不涉及数据的存储或传输。
【演示视频】
|









 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 创客造
创客造
 编辑选择奖
编辑选择奖
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






