|
18716| 25
|
[MP动手做] MicroPython动手做(25)——语音合成与语音识别 |
|
本帖最后由 驴友花雕 于 2020-5-22 07:02 编辑 1、TTS(Text-To-Speech,文本到语音) TTS是Text To Speech的缩写,即“从文本到语音”,是人机对话的一部分,将文本转化问文字,让机器能够说话。我们比较熟悉的ASR(Automatic Speech Recognition),是将声音转化为文字,可类比于人类的耳朵。而TTS是将文字转化为声音(朗读出来),类比于人类的嘴巴,是人机对话的一部分,让机器能够说话。 TTS是同时运用语言学和心理学的杰出之作,在内置芯片的支持之下,通过神经网络的设计,把文字智能地转化为自然语音流。TTS技术对文本文件进行实时转换,转换时间之短可以秒计算。在其特有智能语音控制器作用下,文本输出的语音音律流畅,使得听者在听取信息时感觉自然,毫无机器语音输出的冷漠与生涩感。TTS语音合成技术 [1] 即将覆盖国标一、二级汉字,具有英文接口,自动识别中、英文,支持中英文混读。所有声音采用真人普通话为标准发音,实现了120-150个汉字/分钟的快速语音合成,朗读速度达3-4个汉字/秒,使用户可以听到清晰悦耳的音质和连贯流畅的语调。有少部分MP3随身听具有了TTS功能。  附:什么是人工智能? 顾名思义就是由人创造的"智慧能力",具备听说看理解等能力。 听 ==语音识别 说 ==语音合成 看 ==图像视频文字识别 理解 ==语言(文字)图像视频理解等逻辑处理 思考 ==理解后的逻辑处理 |
|
今天再次测试语音合成,不知为何一直报错,出错信息为: 刷入成功 Connection WiFi.... WiFi(zhz,-64dBm) Connection Successful, Config:('192.168.31.25', '255.255.255.0', '192.168 .31.34', '192.168.31.34') (2020, 6, 15, 8, 28, 32, 0, 167) Processing, please wait.... Traceback (most recent call last): File "main.py", line 24, in <module> File "xunfei.py", line 208, in tts File "uwebsockets/client.py", line 62, in connect Assertion Error: b'HTTP/1.1 403 Forbidden' MicroPython v2.0.1-18-gbe8fbdd-dirty on 2020-04-24; mpython with ESP32 Type "help()" for more information. >>> >>>  |
|
10、语音控制开灯与关灯 ——简单在线模式,反应有点慢,语音识别“开灯”,任意语音关灯。这个方案打开灯有点难,需要准确发音“开灯”二个字,反之关灯很容易,说什么都可以关灯,便于节约用电。 [mw_shl_code=python,false]#MicroPython动手做(25)——语音合成与语音识别 #语音控制开灯与关灯(简单在线模式,反应有点慢) from mpython import * import network import music import time import audio import urequests import json import machine import ubinascii my_wifi = wifi() my_wifi.connectWiFi("zh", "zy1567") def on_button_a_down(_): time.sleep_ms(10) if button_a.value() == 1: return rgb[1] = (int(102), int(0), int(0)) rgb.write() time.sleep_ms(1) if get_asr_result(2) == "开灯": rgb.fill((int(51), int(102), int(255))) rgb.write() time.sleep_ms(1) music.play('D5:1') oled.fill(0) oled.blit(image_picture.load('face/Objects/Light on.pbm', 0), 32, 0) oled.show() else: rgb.fill( (0, 0, 0) ) rgb.write() time.sleep_ms(1) music.play('B5:1') oled.fill(0) oled.blit(image_picture.load('face/Objects/Light off.pbm', 0), 32, 0) oled.show() def get_asr_result(_time): audio.recorder_init() audio.record("temp.wav", int(_time)) audio.recorder_deinit() _response = urequests.post("http://119.23.66.134:8085/file_upload", files={"file":("temp.wav", "audio/wav")}, params={"appid":"1", "mediatype":"2", "deviceid":ubinascii.hexlify(machine.unique_id()).decode().upper()}) rsp_json = _response.json() _response.close() if "text" in rsp_json: return rsp_json["text"] elif "Code" in rsp_json: return "Code:%s" % rsp_json["Code"] else: return rsp_json image_picture = Image() button_a.irq(trigger=Pin.IRQ_FALLING, handler=on_button_a_down) oled.fill(0) oled.DispChar(" 按下A键开始语音控制", 0, 16, 1) oled.show() music.play('G5:1') rgb[1] = (int(0), int(51), int(0)) rgb.write() time.sleep_ms(1)[/mw_shl_code] |
|
6、AB按键切换语言合成项目 [mw_shl_code=python,false]#MicroPython动手做(25)——语音合成与语音识别 #AB按键切换语言合成项目 from mpython import * import network import time import ntptime from xunfei import * import audio my_wifi = wifi() my_wifi.connectWiFi("zh", "zy1567") def on_button_a_down(_): global Audio, Text time.sleep_ms(10) if button_a.value() == 1: return rgb[0] = (int(102), int(0), int(0)) rgb.write() time.sleep_ms(1) Text = "A键被按下" Audio = "tts.pcm" speech_tts = Xunfei_speech("5ec66b", "5d32b259f15b2902d81b9efd22926", "3aace39c0ecea76ef46a200300826", mode=MODE_TTS, AudioFile=Audio, Text=Text) print("Processing, please wait....") speech_tts.tts() oled.fill(0) oled.DispChar(" A键被按下", 0, 16, 1) oled.show() audio.player_init() audio.set_volume(120) audio.play(Audio) time.sleep(2) oled.fill(0) rgb[0] = (0, 0, 0) rgb.write() time.sleep_ms(1) oled.show() def on_button_b_down(_): global Audio, Text time.sleep_ms(10) if button_b.value() == 1: return rgb[2] = (int(102), int(0), int(0)) rgb.write() time.sleep_ms(1) Text = "B键被按下" Audio = "tts.pcm" speech_tts = Xunfei_speech("5ec66b", "5d32b259f15b2902d81b9efd22926", "3aace39c0ecea76ef46a200300826", mode=MODE_TTS, AudioFile=Audio, Text=Text) print("Processing, please wait....") speech_tts.tts() oled.fill(0) oled.DispChar(" B键被按下", 0, 16, 1) oled.show() audio.player_init() audio.set_volume(120) audio.play(Audio) time.sleep(2) oled.fill(0) rgb[2] = (0, 0, 0) rgb.write() time.sleep_ms(1) oled.show() button_a.irq(trigger=Pin.IRQ_FALLING, handler=on_button_a_down) button_b.irq(trigger=Pin.IRQ_FALLING, handler=on_button_b_down) rgb[1] = (int(0), int(51), int(0)) rgb.write() time.sleep_ms(1) while True: try: ntptime.settime(8, "time.windows.com") break except: pass[/mw_shl_code] |
|
2、语音合成(SpeechSynthesis) 语音合成,能将任意文字信息实时转化为标准流畅的语音朗读出来,相当于给机器装上了人工嘴巴。它涉及声学、语言学、数字信号处理、计算机科学等多个学科技术,是中文信息处理领域的一项前沿技术,解决的主要问题就是如何将文字信息转化为可听的声音信息,也即让机器像人一样开口说话。我们所说的“让机器像人一样开口说话”与传统的声音回放设备(系统)有着本质的区别。传统的声音回放设备(系统),如磁带录音机,是通过预先录制声音然后回放来实现“让机器说话”的。这种方式无论是在内容、存储、传输或者方便性、及时性等方面都存在很大的限制。而通过计算机语音合成则可以在任何时候将任意文本转换成具有高自然度的语音,从而真正实现让机器“像人一样开口说话”。 语音合成是通过机械的、电子的方法产生人造语音的技术。TTS技术(又称文语转换技术)隶属于语音合成,它是将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的汉语口语输出的技术。TTS将储存于电脑中的文件,如帮助文件或者网页,转换成自然语音输出。TTS不仅能帮助有视觉障碍的人阅读计算机上的信息,更能增加文本文档的可读性。TTS应用包括语音驱动的邮件以及声音敏感系统,并常与声音识别程序一起使用。语音合成满足将文本转化成拟人化语音的需求,打通人机交互闭环。 提供多种音色选择,支持自定义音量、语速,让发音更自然、更专业、更符合场景需求。语音合成广泛应用于语音导航、有声读物、机器人、语音助手、自动新闻播报等场景,提升人机交互体验,提高语音类应用构建效率。  |
|
3、TTS一般分为两个步骤 (1) 文本处理。这一步做的事情是把文本转化成音素序列,并标出每个音素的起止时间、频率变化等信息。作为一个预处理步骤,它的重要性经常被忽视,但是它涉及到很多值得研究的问题,比如拼写相同但读音不同的词的区分、缩写的处理、停顿位置的确定,等等。 (2)语音合成。狭义上这一步专指根据音素序列(以及标注好的起止时间、频率变化等信息)生成语音,广义上它也可以包括文本处理的步骤。这一步主要有三类方法: a、拼接法,即从事先录制的大量语音中,选择所需的基本单位拼接而成。这样的单位可以是音节、音素等等;为了追求合成语音的连贯性,也常常用使用双音子(从一个音素的中央到下一个音素的中央)作为单位。拼接法合成的语音质量较高,但它需要录制大量语音以保证覆盖率。 b、参数法,即根据统计模型来产生每时每刻的语音参数(包括基频、共振峰频率等),然后把这些参数转化为波形。参数法也需要事先录制语音进行训练,但它并不需要100%的覆盖率。参数法合成出的语音质量比拼接法差一些。 c、声道模拟法。参数法利用的参数是语音信号的性质,它并不关注语音的产生过程。与此相反,声道模拟法则是建立声道的物理模型,通过这个物理模型产生波形。这种方法的理论看起来很优美,但由于语音的产生过程实在是太复杂,所以实用价值并不高。  |
|
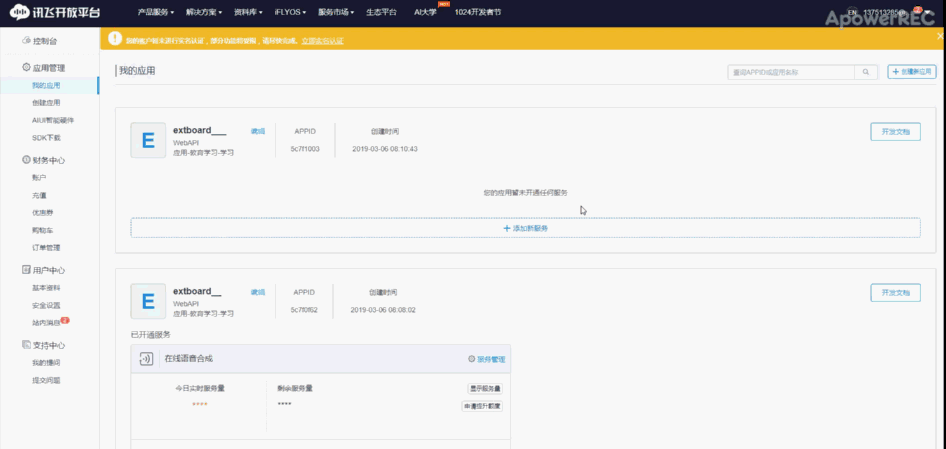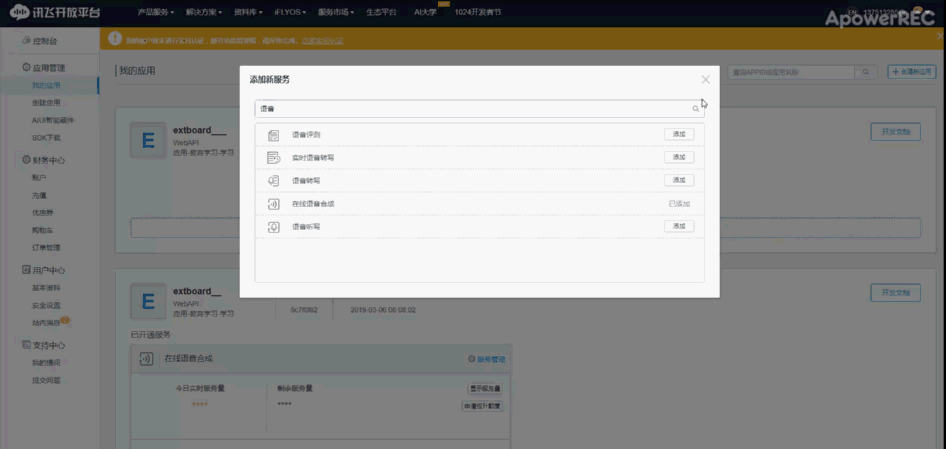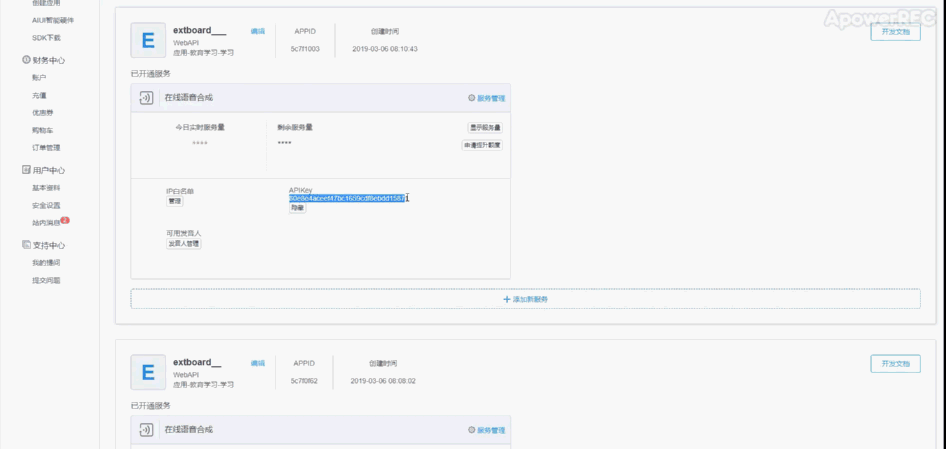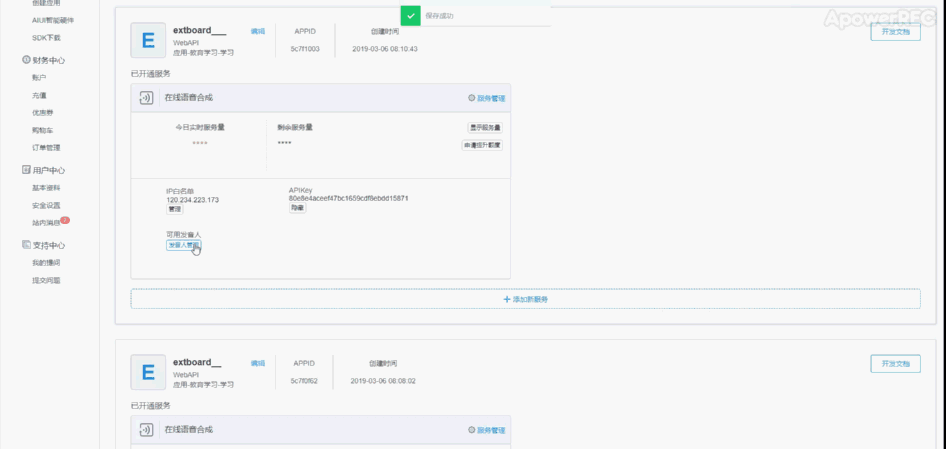
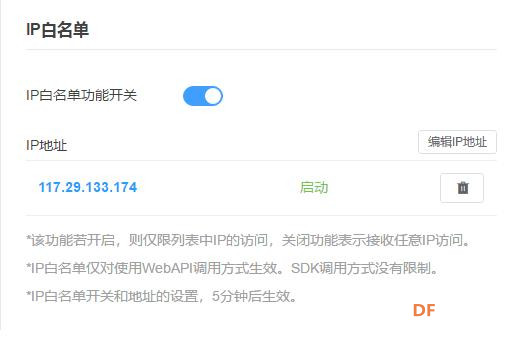
4、在讯飞开放平台注册 TTS是Text To Speech的缩写,即“从文本到语音”,是人机对话的一部分,将文本转化问文字,让机器能够说话。 掌控拓展板的在线语音合成功能是使用 讯飞在线语音合成API(https://www.xfyun.cn/services/online_tts) ,用户在使用该功能前,需要在讯飞开放平台注册并做相应的配置。 步骤1.在讯飞 https://www.xfyun.cn 注册账号。 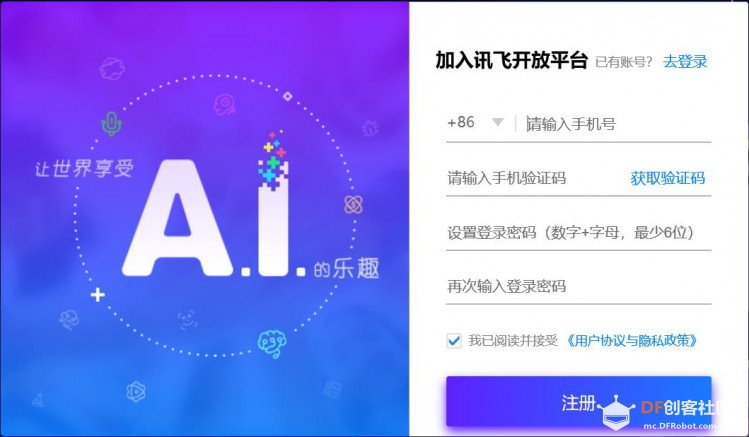 |
|
5、文字转语音 #MicroPython动手做(25)——语音合成与语音识别 注意 首先使用 ntptime.settime() 校准RTC时钟。 TTS支持中英文的文本转换。你可以将你想要说话的内容,通过文本的形式转化为语音。这样你就可以给你掌控板添上“人嘴”,模拟人机对话场景。
|
|
[mw_shl_code=python,false]#MicroPython动手做(25)——语音合成与语音识别 #测试文字转语音 from mpython import * import network import ntptime from xunfei import * import audio my_wifi = wifi() my_wifi.connectWiFi("zh", "zy1567") while True: try: ntptime.settime(8, "time.windows.com") break except: pass Text = "掌控板TTS文字转语音以及语音识别" Audio = "tts.pcm" speech_tts = Xunfei_speech("5ec66b", "5d32b259f15b2902d81b9efd22926", "3aace39c0ecea76ef46a200300826", mode=MODE_TTS, AudioFile=Audio, Text=Text) print("Processing, please wait....") speech_tts.tts() audio.player_init() audio.set_volume(100) audio.play(Audio)[/mw_shl_code] |
本帖最后由 驴友花雕 于 2020-5-22 20:12 编辑  7、语音识别 说 ==语音合成(文字转为语音) 听 ==语音识别(语音转为文字) 语音识别是一门交叉学科。近二十年来,语音识别技术取得显著进步,开始从实验室走向市场。人们预计,未来10年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。 语音识别听写机在一些领域的应用被美国新闻界评为1997年计算机发展十件大事之一。很多专家都认为语音识别技术是2000年至2010年间信息技术领域十大重要的科技发展技术之一。 语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。 与机器进行语音交流,让机器明白你说什么,这是人们长期以来梦寐以求的事情。中国物联网校企联盟形象得把语音识别比做为“机器的听觉系统”。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。 语音识别技术主要包括特征提取技术、模式匹配准则及模型训练技术三个方面。语音识别技术车联网也得到了充分的引用,例如在翼卡车联网中,只需按一键通客服人员口述即可设置目的地直接导航,安全、便捷。 |
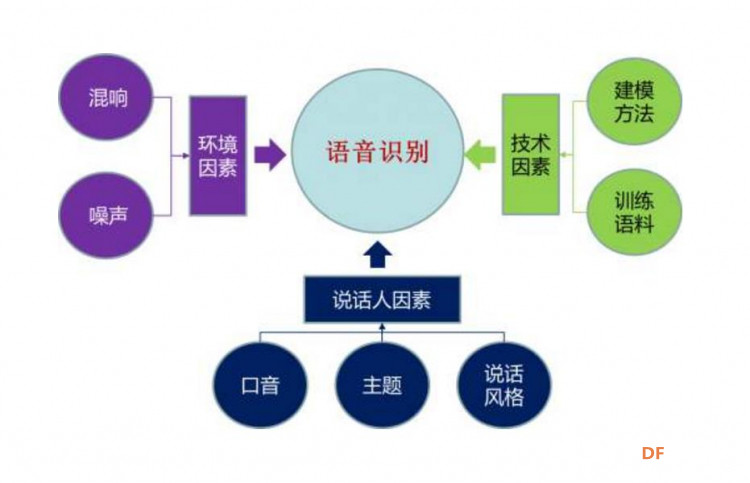 语音识别发展史 1952年贝尔研究所Davis等人研究成功了世界上第一个能识别10个英文数字发音的实验系统。1960年英国的Denes等人研究成功了第一个计算机语音识别系统。大规模的语音识别研究是在进入了70年代以后,在小词汇量、孤立词的识别方面取得了实质性的进展。进入80年代以后,研究的重点逐渐转向大词汇量、非特定人连续语音识别。在研究思路上也发生了重大变化,即由传统的基于标准模板匹配的技术思路开始转向基于统计模型 (HMM)的技术思路。此外,再次提出了将神经网络技术引入语音识别问题的技术思路。进入90年代以后,在语音识别的系统框架方面并没有什么重大突破。但是,在语音识别技术的应用及产品化方面出现了很大的进展。DARPA(Defense Advanced Research Projects Agency)是在70年代由美国国防部远景研究计划局资助的一项10年计划,其旨在支持语言理解系统的研究开发工作。到了80年代,美国国防部远景研究计划局又资助了一项为期10年的DARPA战略计划,其中包括噪声下的语音识别和会话(口语)识别系统,识别任务设定为“(1000单词)连续语音数据库管理”。到了90年代,这一DARPA计划仍在持续进行中。其研究重点已转向识别装置中的自然语言处理部分,识别任务设定为“航空旅行信息检索”。日本也在1981年的第五代计算机计划中提出了有关语音识别输入-输出自然语言的宏伟目标,虽然没能实现预期目标,但是有关语音识别技术的研究有了大幅度的加强和进展。1987年起,日本又拟出新的国家项目---高级人机口语接口和自动电话翻译系统。 语音识别在中国的发展 中国的语音识别研究起始于1958年,由中国科学院声学所利用电子管电路识别10个元音。直至1973年才由中国科学院声学所开始计算机语音识别。由于当时条件的限制,中国的语音识别研究工作一直处于缓慢发展的阶段。进入80年代以后,随着计算机应用技术在中国逐渐普及和应用以及数字信号技术的进一步发展,国内许多单位具备了研究语音技术的基本条件。与此同时,国际上语音识别技术在经过了多年的沉寂之后重又成为研究的热点,发展迅速。就在这种形式下,国内许多单位纷纷投入到这项研究工作中去。1986年3月中国高科技发展计划(863计划)启动,语音识别作为智能计算机系统研究的一个重要组成部分而被专门列为研究课题。在863计划的支持下,中国开始了有组织的语音识别技术的研究,并决定了每隔两年召开一次语音识别的专题会议。从此中国的语音识别技术进入了一个前所未有的发展阶段。 |
|
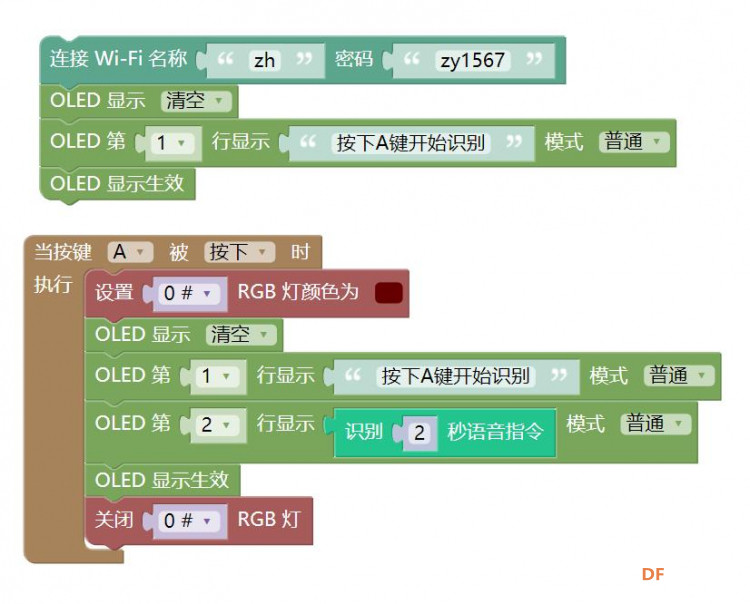
8、识别二秒语音指令(现录现识别) [mw_shl_code=python,false]#MicroPython动手做(25)——语音合成与语音识别 #识别二秒语音指令(现录现识别) from mpython import * import network import time import audio import urequests import json import machine import ubinascii my_wifi = wifi() my_wifi.connectWiFi("zh", "zy1567") def on_button_a_down(_): time.sleep_ms(10) if button_a.value() == 1: return rgb[0] = (int(102), int(0), int(0)) rgb.write() time.sleep_ms(1) oled.fill(0) oled.DispChar("按下A键开始识别", 0, 0, 1) oled.DispChar(get_asr_result(2), 0, 16, 1) oled.show() rgb[0] = (0, 0, 0) rgb.write() time.sleep_ms(1) def get_asr_result(_time): audio.recorder_init() audio.record("temp.wav", int(_time)) audio.recorder_deinit() _response = urequests.post("http://119.23.66.134:8085/file_upload", files={"file":("temp.wav", "audio/wav")}, params={"appid":"1", "mediatype":"2", "deviceid":ubinascii.hexlify(machine.unique_id()).decode().upper()}) rsp_json = _response.json() _response.close() if "text" in rsp_json: return rsp_json["text"] elif "Code" in rsp_json: return "Code:%s" % rsp_json["Code"] else: return rsp_json button_a.irq(trigger=Pin.IRQ_FALLING, handler=on_button_a_down) oled.fill(0) oled.DispChar("按下A键开始识别", 0, 0, 1) oled.show()[/mw_shl_code] |
|
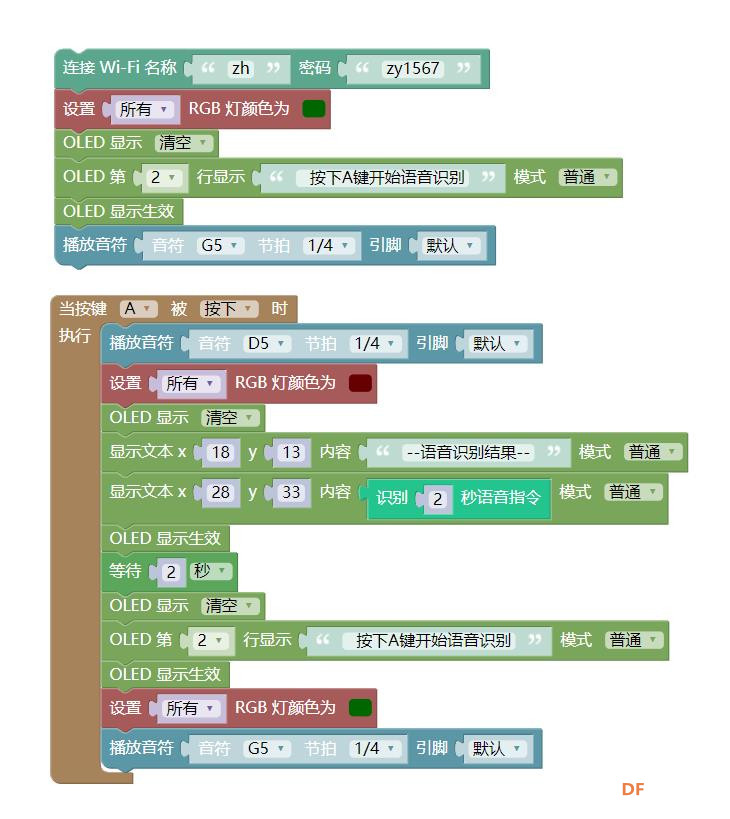
9、带提示音提示灯的简单语音识别系统 (红灯后识别二秒钟) [mw_shl_code=python,false]#MicroPython动手做(25)——语音合成与语音识别 #带提示音提示灯的简单语音识别系统(红灯后识别二秒钟) from mpython import * import network import time import music import audio import urequests import json import machine import ubinascii my_wifi = wifi() my_wifi.connectWiFi("zh", "zy1567") def on_button_a_down(_): time.sleep_ms(10) if button_a.value() == 1: return music.play('D5:1') rgb.fill((int(102), int(0), int(0))) rgb.write() time.sleep_ms(1) oled.fill(0) oled.DispChar("--语音识别结果--", 18, 13, 1) oled.DispChar(get_asr_result(2), 28, 33, 1) oled.show() time.sleep(2) oled.fill(0) oled.DispChar(" 按下A键开始语音识别", 0, 16, 1) oled.show() rgb.fill((int(0), int(102), int(0))) rgb.write() time.sleep_ms(1) music.play('G5:1') def get_asr_result(_time): audio.recorder_init() audio.record("temp.wav", int(_time)) audio.recorder_deinit() _response = urequests.post("http://119.23.66.134:8085/file_upload", files={"file":("temp.wav", "audio/wav")}, params={"appid":"1", "mediatype":"2", "deviceid":ubinascii.hexlify(machine.unique_id()).decode().upper()}) rsp_json = _response.json() _response.close() if "text" in rsp_json: return rsp_json["text"] elif "Code" in rsp_json: return "Code:%s" % rsp_json["Code"] else: return rsp_json button_a.irq(trigger=Pin.IRQ_FALLING, handler=on_button_a_down) rgb.fill((int(0), int(102), int(0))) rgb.write() time.sleep_ms(1) oled.fill(0) oled.DispChar(" 按下A键开始语音识别", 0, 16, 1) oled.show() music.play('G5:1')[/mw_shl_code] |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶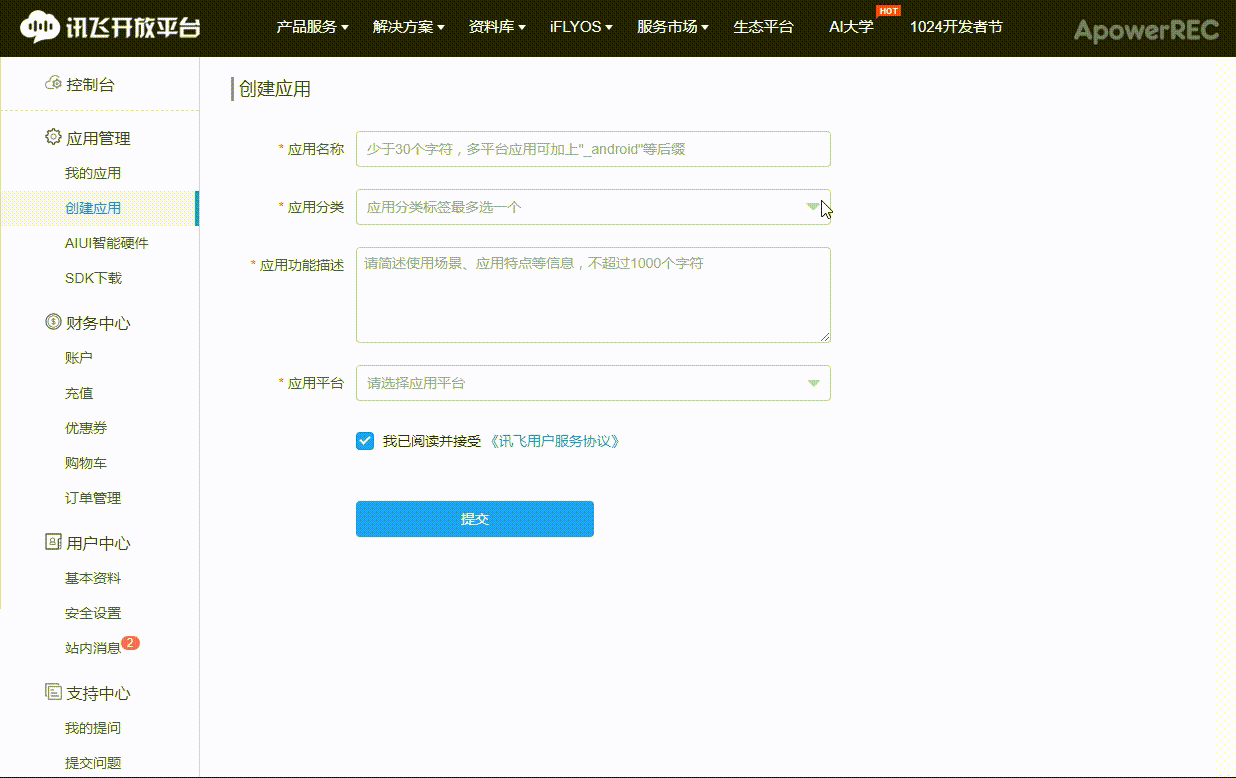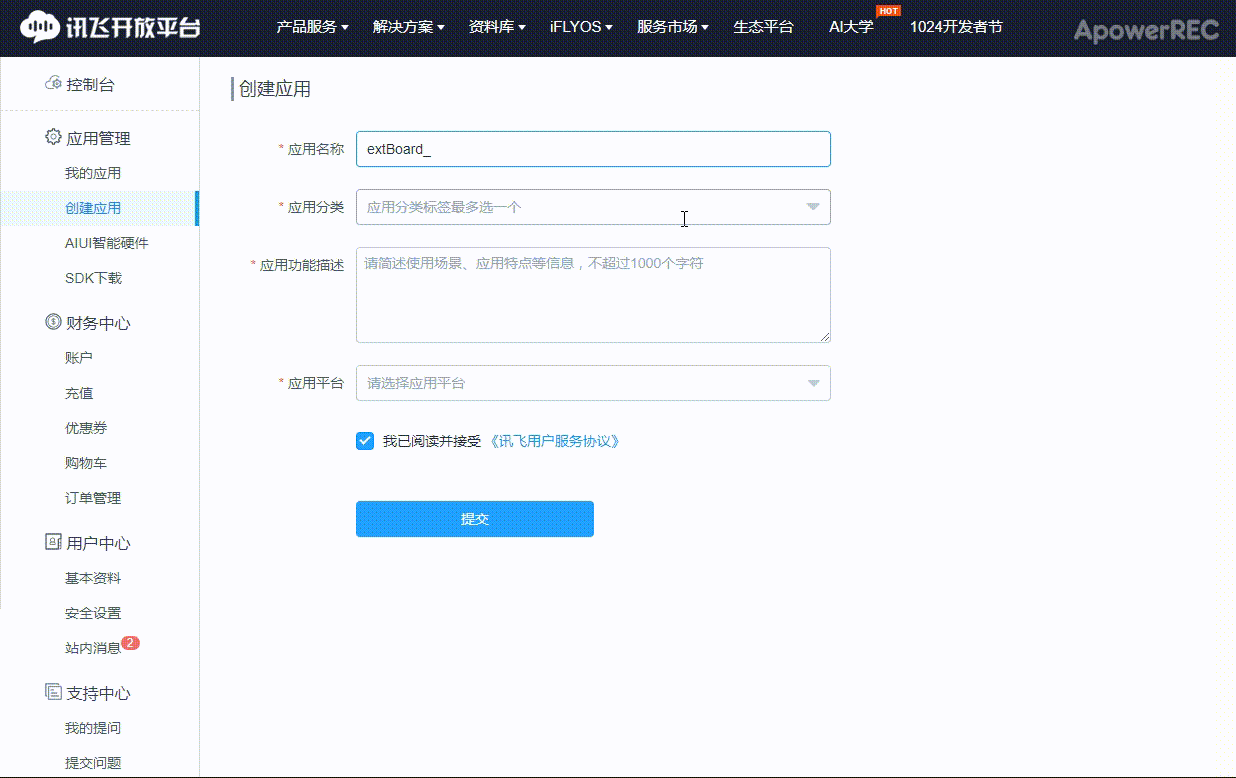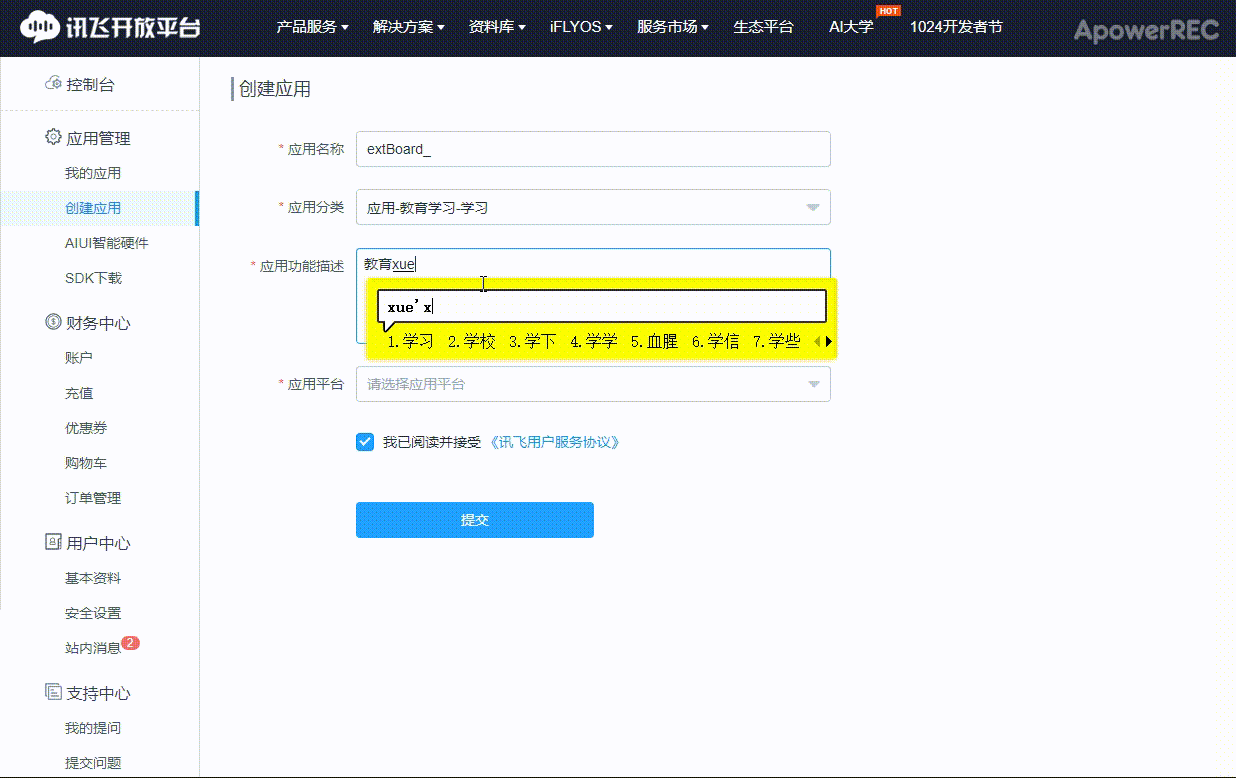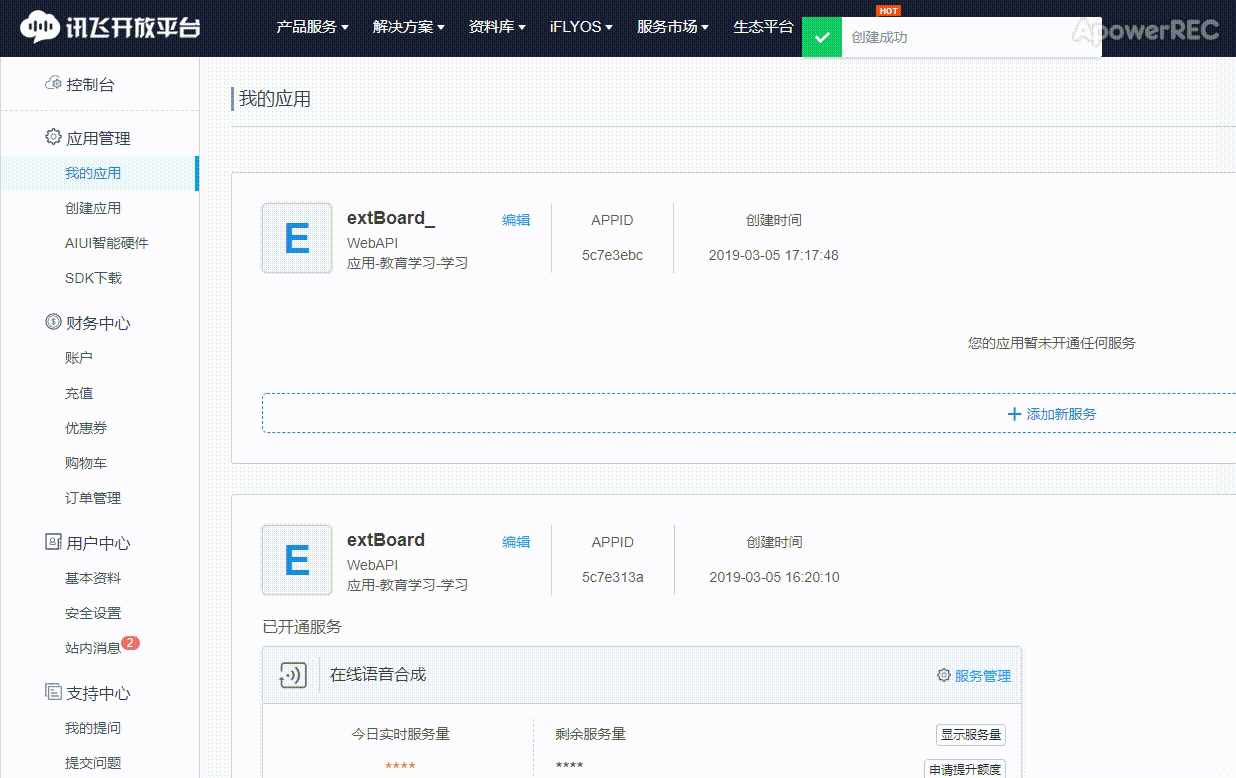





 萌萌哒新人
萌萌哒新人
 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 创作达人
创作达人
 ARD DAY
ARD DAY
 摸鱼团员
摸鱼团员
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖






