|
4396| 0
|
[官方资料] Jetson Nano 2GB 系列文章(24): “Hello AI World” 的物件识别应用 |

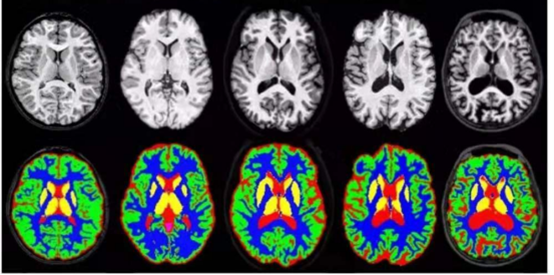
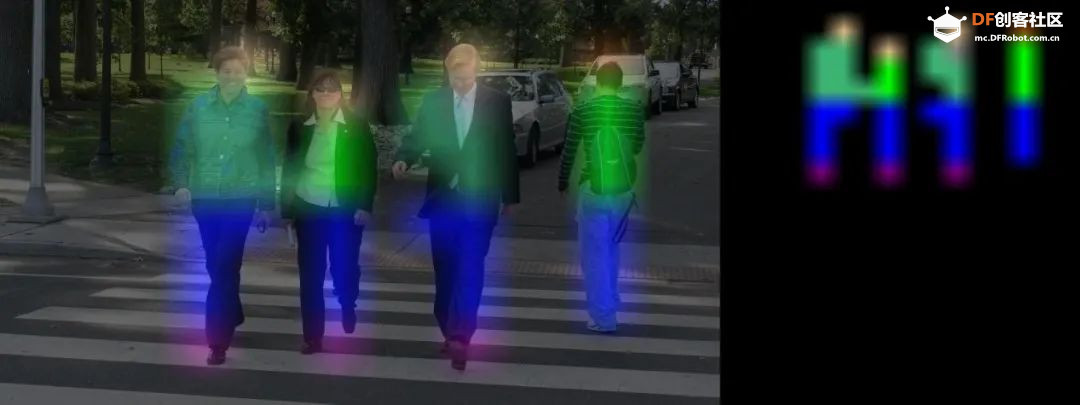
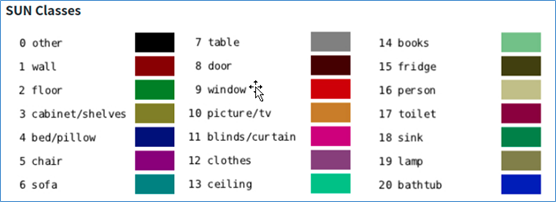
本系列最后一个需要说明的推理识别应用,就是语义分割(semantic segmentation)的推理识别,字面上经常造成初学者的误解,以为这是语音语义识别相关的应用。现在我们看看下面的一张图片,就比较能理解语义分割的应用是什么。 在这张图中,可以看到每种“类别”是用“颜色”做区隔,并且每个物件已不再是“矩形框”的标注方式,而是完全将物件的原本形状都标示出来,如此就能更进一步地用计算机视觉的方式,将“全场景”与“物件”之间,形成信息量更完整的“语义”表述。 这类的应用场景,大部分都是“专业”用途,例如医学成像、肿瘤分析、航拍识别、无人驾驶、城市规划之类,对“精确度”要求更高的应用,属于“像素级”的推理识别,其难度与计算量,比前面的图像分类、物件检测要高出许多,对初学者来说,只要简单体验一下就可以。 Hello AI World 项目为语义分割应用,也同样提供 segnet 指令与 segnet.py 代码,二者的使用方式与功能是相同的,指令的主要参数列表条列如下,其中黄色标出的部分是比较重要的参数: --network 参数应该是很熟悉了,项目也为这个应用提供 11 个预训练模型可轻松调用(如下表): 系统预设的网络模型是 FCN-ResNet18-Pascal-VOC-320x320(Pascal VOC 320x320),这是个比较通用类的模型。 前面提过,语义分割的推理识别,最终以“颜色”来进行分类的显示,而每种模型的分类与对应颜色都不一样,所以必须有这样的对照表去比对。在 ~/jetson-inference/data/networks 下面有多个 “FCN-” 带头的子目录,下面放的都是 segnet 使用的预训练模型文件,以及 “classes.txt” 与 “colors.txt” 这两个类别与颜色的对应表,请自行参考内容。 不同模型的针对性都不同,例如系统预设的 Pascal VOC 模型属于比较通用的,其类别与颜色对照表如下: 现在以 ~/jetson-inference/data/images/peds_0.jpg (如下图)为对象,来进行不同模型的测试结果。 执行以下指令: 执行结果如下图: 这边识别出“四个人”并且用对应的颜色显示出来。左边的图就是前面说到 “--visualize=overlay” 时的表示方法,将颜色与原图进行“重叠(overlay)”显示;右边部分是 “--visulaize=mask” 的显示结果,只显示检测到的部分,未检测到的地方则全部“遮盖(mask)”掉。 如果将网络模型改成 Cityscape 的话,看看会呈现怎样的结果? 执行结果如下图,在右上角的示图中,好像整个图像都有对应的分类。 下面是 Cityscape 的类别/颜色对照表: 看看里面的类别有包括 “ground(地面)”、“road(道路)”、“sidewalk(人行道)”、“vegetation(植被)”这些类别,这个模型主要应用在城市交通与建设方面的应用,因此几乎能做到“全景分类”的功能。 接着再试试将网络模型改成 Multi-Human 类型,执行以下指令: 执行的结果如下图,右上角的示图中也只是将“人”的部分显示出来: 不过有点特别的是,好像在“人身上”的部分,有更细微的分类,例如图中最明显的“蓝色”部分,对应下面的对照表,发现属于 “pants(裤子)”类别;在蓝色底下有 “shoe/boot” 的颜色分类,左边三个物体的顶端,呈现 “face” 的颜色分类。 这里非常明显地展示出,不同模型有个别的针对重点,例如在支持的模型列表最后面的 “SUN RGB-D”,主要针对“室内家具”的分类,其分类颜色类别如下: 试试看执行下面指令,会得到怎样的结果: 检测出来的结果似乎正确性并不高,如果将测试图片改成 room_*.jpg 的话,应该会得到比较好的效果,请自行测试一下。 至于下面三个参数的变化,请自行测试: -- visualize 参数:可指定为 “overlay(重叠)”或“mask(遮盖)” 以上就是 Hello AI World 提供的 segnet 与 segnet.py 测试工具的使用方式,至于代码级别的 segNet() 相对复杂,有兴趣的可以直接参考 segnet.py 代码,并且参考前面有关 imageNet() 与 detectNet() 的代码文章,自行测试看看。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed















 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






