本帖最后由 云天 于 2021-2-27 13:44 编辑
【准备工作】
参考:https://mc.dfrobot.com.cn/thread-308419-1-1.html
【项目目的】
利用乐高EV3语音播报新闻
【ev3dev中speak方法】
在ev3dev中的sound库中有speak方法,可以进行朗读,但它只能朗读英语。
- def speak(self, text, espeak_opts='-a 200 -s 130', volume=100, play_type=PLAY_WAIT_FOR_COMPLETE):
- """ Speak the given text aloud.
-
- Uses the ``espeak`` external command.
-
- :param string text: The text to speak
- :param string espeak_opts: ``espeak`` command options (advanced usage)
- :param int volume: The play volume, in percent of maximum volume
-
- :param play_type: The behavior of ``speak`` once playback has been initiated
- :type play_type: ``Sound.PLAY_WAIT_FOR_COMPLETE``, ``Sound.PLAY_NO_WAIT_FOR_COMPLETE`` or ``Sound.PLAY_LOOP``
-
- :return: When python3 is used and ``Sound.PLAY_NO_WAIT_FOR_COMPLETE`` is specified, returns the
- spawn subprocess from ``subprocess.Popen``; ``None`` otherwise
- """
- self._validate_play_type(play_type)
- self.set_volume(volume)
- cmd = "/usr/bin/espeak --stdout %s '%s' | /usr/bin/aplay -q" % (espeak_opts, text)
- return self._audio_command(cmd, play_type)
python程序
- from ev3dev2.sound import Sound
- sound=Sound()
- sound.speak('I Love You',volume=20)
换个思路,将文字传给百度AI平台进行语音合成,EV3使用ev3dev中的sound库播放传回来的音频文件。
【清理python2.7】
在乐高EV3的ev3dev中安装有python2.7和python3.7,使用pip安装时,会安装到python2.7中。我要使用python3,而pip3并不存在。通过以下方法,先删除python2.7,再安装python3.7下的pip3.
- 1.卸载python2.7sudo apt-get remove python2.7
- 2.卸载python2.7及其依赖sudo apt-get remove --auto-remove python2.7
- 3.消除python2.7sudo apt-get purge python2.7 or sudo apt-get purge --auto-remove python2.7
- 4、安装pip3:
- sudo apt install python3-pip
- 5、更新pip3。
有网友说在Python可以使用用playsound module:playsound module是一个可以跨平台使用的库,不需要其他依赖的库,直接利用pip或者IDE的库管理功能安装就行。
复制代码
使用此方法在乐高EV3 并不能播放由百度传来的mp3。
【使用sound库】
- class Sound(object):
- """
- Support beep, play wav files, or convert text to speech.
-
- Examples::
-
- from ev3dev2.sound import Sound
-
- spkr = Sound()
-
- # Play 'bark.wav':
- spkr.play_file('test.wav')
-
- # Introduce yourself:
- spkr.speak('Hello, I am Robot')
-
- # Play a small song
- spkr.play_song((
- ('D4', 'e3'),
- ('D4', 'e3'),
- ('D4', 'e3'),
- ('G4', 'h'),
- ('D5', 'h')
- ))
- def play_file(self, wav_file, volume=100, play_type=PLAY_WAIT_FOR_COMPLETE):
- """ Play a sound file (wav format) at a given volume. The EV3 audio subsystem will work best if
- the file is encoded as 16-bit, mono, 22050Hz.
-
- :param string wav_file: The sound file path
- :param int volume: The play volume, in percent of maximum volume
-
- :param play_type: The behavior of ``play_file`` once playback has been initiated
- :type play_type: ``Sound.PLAY_WAIT_FOR_COMPLETE``, ``Sound.PLAY_NO_WAIT_FOR_COMPLETE`` or ``Sound.PLAY_LOOP``
-
- :return: When python3 is used and ``Sound.PLAY_NO_WAIT_FOR_COMPLETE`` is specified, returns the
- spawn subprocess from ``subprocess.Popen``; ``None`` otherwise
- """
- if not 0 < volume <= 100:
- raise ValueError('invalid volume (%s)' % volume)
-
- if not wav_file.endswith(".wav"):
- raise ValueError('invalid sound file (%s), only .wav files are supported' % wav_file)
-
- if not os.path.exists(wav_file):
- raise ValueError("%s does not exist" % wav_file)
-
- self._validate_play_type(play_type)
- self.set_volume(volume)
- return self._audio_command('/usr/bin/aplay -q "%s"' % wav_file, play_type)
在ev3dev中有sound库,但它只能播放wav格式。而百度语音合成之后的是mp3格式。需要将mp3转成wav。
可使用ffmpeg
【安装ffmpeg】
- sudo add-apt-repository ppa:kirillshkrogalev/ffmpeg-next
- sudo apt-get update
- sudo apt-get install ffmpeg
例如:
-
- from os import path
- from pydub import AudioSegment
- #files
- src = "1.mp3"
- dst = "test.wav"
-
- # convert wav to mp3
- sound = AudioSegment.from_mp3(src)
- sound.export(dst, format="wav")
【百度语音合成】
1、创建应用
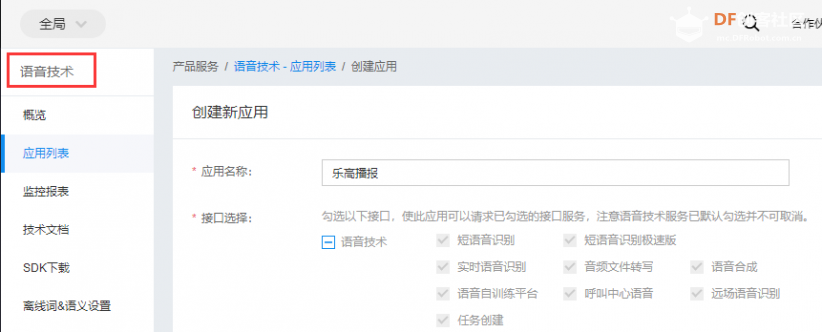
2、获取相应参数
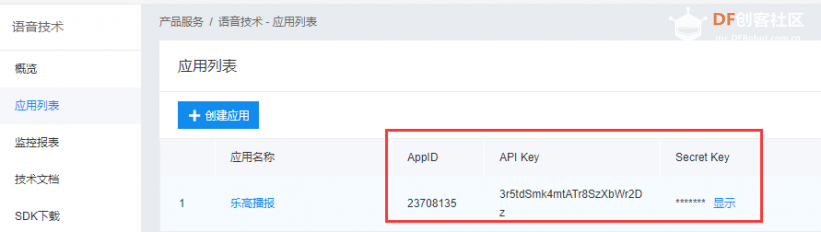
3、安装语音合成 Python SDK
复制代码
[color=rgba(0, 0, 0, 0.85)]AipSpeech是语音合成的Python SDK客户端,为使用语音合成的开发人员提供了一系列的交互方法。
- from aip import AipSpeech
-
- """ 你的 APPID AK SK """
- APP_ID = '你的 App ID'
- API_KEY = '你的 Api Key'
- SECRET_KEY = '你的 Secret Key'
-
- client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
请求说明- 合成文本长度必须小于1024字节,如果本文长度较长,可以采用多次请求的方式。文本长度不可超过限制
[color=rgba(0, 0, 0, 0.85)]举例,要把一段文字合成为语音文件: -
- result = client.synthesis('你好百度', 'zh', 1, {
- 'vol': 5,
- })
-
- # 识别正确返回语音二进制 错误则返回dict 参照下面错误码
- if not isinstance(result, dict):
- with open('audio.mp3', 'wb') as f:
- f.write(result)
【测试程序】- from aip import AipSpeech
- from os import path
- from pydub import AudioSegment
- from ev3dev2.sound import Sound
- """ 你的 APPID AK SK """
- APP_ID = '你自己的'
- API_KEY = '你自己的'
- SECRET_KEY = '你自己的'
-
- client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
- result = client.synthesis('你好百度', 'zh', 1, {
- 'vol': 5,
- })
-
- # 识别正确返回语音二进制 错误则返回dict 参照下面错误码
- if not isinstance(result, dict):
- with open('audio.mp3', 'wb') as f:
- f.write(result)
- src = "audio.mp3"
- dst = "audio.wav"
-
- # convert wav to mp3
- sound = AudioSegment.from_mp3(src)
- sound.export(dst, format="wav")
- spkr = Sound()
- spkr.play_file(dst,volume=20)
【爬取新闻标题】
BS4全称是Beatiful Soup,它提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为tiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。
1、安装
- pip3 install Beautifulsoup4
2、测试程序
-
-
- from bs4 import BeautifulSoup
- import requests
- import time
- from ev3dev2.display import Display
-
- display=Display()
-
- url = "http://news.baidu.com"
- r = requests.get(url)
- html = r.text
- soup = BeautifulSoup(html, 'html.parser')
-
- li_list = soup.select('.hotnews > ul > li')
-
- for li in li_list:
- a_title = li.a.string
- print(a_title)
- time.sleep(10)
【读百度新闻标题】
-
- from aip import AipSpeech
- from os import path
- from pydub import AudioSegment
- from ev3dev2.sound import Sound
- from bs4 import BeautifulSoup
- import requests
- import time
- from ev3dev2.display import Display
-
-
- APP_ID = '23708135'
- API_KEY = '3r5tdSmk4mtATr8SzXbWr2Dz'
- SECRET_KEY = 'Vgc4DeTAiLnpZ9gGwA86DsKaHyGVedKz'
-
- client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
- display=Display()
-
- url = "http://news.baidu.com"
- r = requests.get(url)
- html = r.text
- soup = BeautifulSoup(html, 'html.parser')
-
- li_list = soup.select('.hotnews > ul > li')
- for li in li_list:
- a_title = li.a.string
- result = client.synthesis(a_title, 'zh', 1, {
- 'vol': 5,
- })
- if not isinstance(result, dict):
- with open('audio.mp3', 'wb') as f:
- f.write(result)
- src = "audio.mp3"
- dst = "audio.wav"
- sound = AudioSegment.from_mp3(src)
- sound.export(dst, format="wav")
- spkr = Sound()
- spkr.play_file(dst,volume=100)
- time.sleep(20)
【获取新闻内容】打印测试,只读取第一段。
-
- from bs4 import BeautifulSoup
- import requests
- import time
-
- # 定义url
- url = "https://share.gmw.cn/guancha/2021-02/25/content_34643362.htm"
- r = requests.get(url)
- r.encoding = 'utf-8'
- html = r.text
- soup = BeautifulSoup(html, 'html.parser')
- # 取出结果div
- myAttrs = {'class': 'u-mainText'}
-
- table = soup.find_all(name='div', attrs=myAttrs)
- l=table[0]
- p=l.find_all('p')
- j = 1
- for x in p:
- if j != 2:
- pass
- else:
- print(x.text)
- j = j + 1
-
【播报新闻视频】
【完整程序】
-
- from aip import AipSpeech
- from pydub import AudioSegment
- from ev3dev2.display import Display
- from ev3dev2.sound import Sound
- from os import path
-
-
- from bs4 import BeautifulSoup
- import requests
- import time
-
-
- APP_ID = '23708135'
- API_KEY = '3r5tdSmk4mtATr8SzXbWr2Dz'
- SECRET_KEY = 'Vgc4DeTAiLnpZ9gGwA86DsKaHyGVedKz'
-
- client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
- display = Display()
-
- url = "http://news.baidu.com"
- r = requests.get(url)
- r.encoding = 'utf-8'
- html = r.text
- soup = BeautifulSoup(html, 'html.parser')
-
- li_list = soup.select('.hotnews > ul > li')
- for li in li_list:
- url = li.a['href']
- r = requests.get(url)
- r.encoding = 'utf-8'
- html = r.text
- soup = BeautifulSoup(html, 'html.parser')
- myAttrs = {'class': 'u-mainText'}
-
- table = soup.find_all(name='div', attrs=myAttrs)
- if len(table)>0:
- l = table[0]
- p = l.find_all('p')
- j = 1
- for x in p:
- if j == 2:
- # print(x.text)
- result = client.synthesis(x.text, 'zh', 1, {'vol': 5})
- if not isinstance(result, dict):
- with open('audio.mp3', 'wb') as f:
- f.write(result)
- src = "audio.mp3"
- dst = "audio.wav"
- sound = AudioSegment.from_mp3(src)
- sound.export(dst, format="wav")
- spkr = Sound()
- spkr.play_file(dst, volume=100)
- else:
- pass
-
- j = j + 1
-
|





 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 创客造
创客造
 编辑选择奖
编辑选择奖
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






