本帖最后由 云天 于 2024-1-18 21:34 编辑
【项目背景】
在2022年的北京冬奥会上,以中国天气节目主持人冯殊为原型的虚拟主播冯小殊亮相荧屏。一张写实的脸,自然的语气和举止,让不少网友感叹,真假难辨神。通过科技服务的方式更好地提升气象服务的质量,而“冯小殊”的加入,也为这场科技冬奥贡献了一份来自AI的力量。《虚拟数字人深度产业报告》显示,到2030年,我国虚拟数字人整体市场规模将达到2700亿元,而当前虚拟人产业还处于培育阶段。
虚拟数字人:是人工智能产物,利用最新的信息科技技术对人体在不同水平的形态和功能进行虚拟仿真。它背后集成了多模态建模、语音识别、知识图谱、视觉技术等综合AI能力,具有一定的逼真效果。
2012年的“虚拟偶像”洛天依,这是二次元的虚拟人,如今的超现实虚拟人,2021年5月,天猫合作打造的首个超写实数字人AYAYI出世,入住小红书一个月内收获了280万浏览量和11.1万点赞收藏,涨粉4.9万,站内千赞转化比达到5以上,9月8日,她正式成为阿里的数字人员工。
【项目设计】
使用行空板结合讯飞的“AI虚拟人技术”(AI 自动预测表情、智能预测口型、实时处理唇形,表情真实,自然生动。支持正常播报和交互动作,并在动作库里为各个应用场景添加了场景特性动作,使虚拟人生动自然。),展示“虚拟人”的简单应用。
项目1:使用两个按钮进行文本驱动,控制虚拟人的相应动作。如让她赞美一下我“这个程序写的真好,你真棒!”。
项目2:使用语音驱动,与虚拟人进行对话。
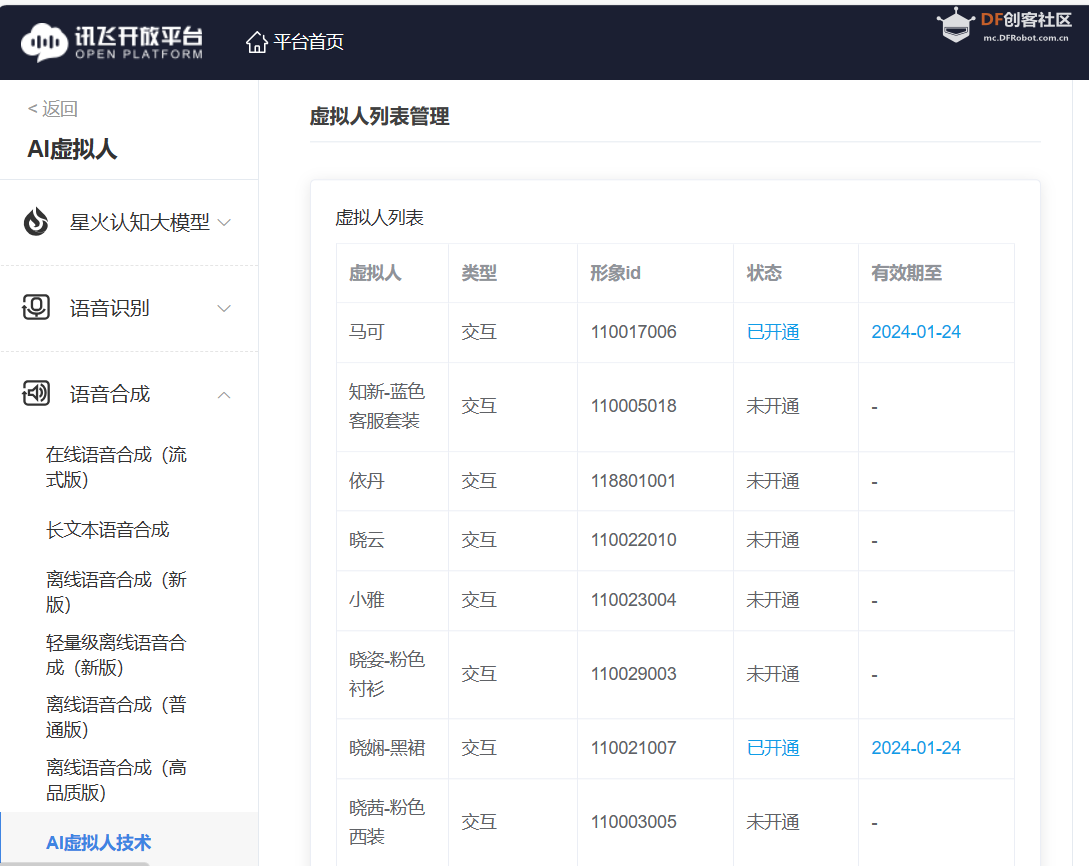
【注册领取虚拟人】
在讯飞开放平台https://console.xfyun.cn/,注册帐号,并领取虚拟人(7天免费使用)控制台-讯飞开放平台 (xfyun.cn)。
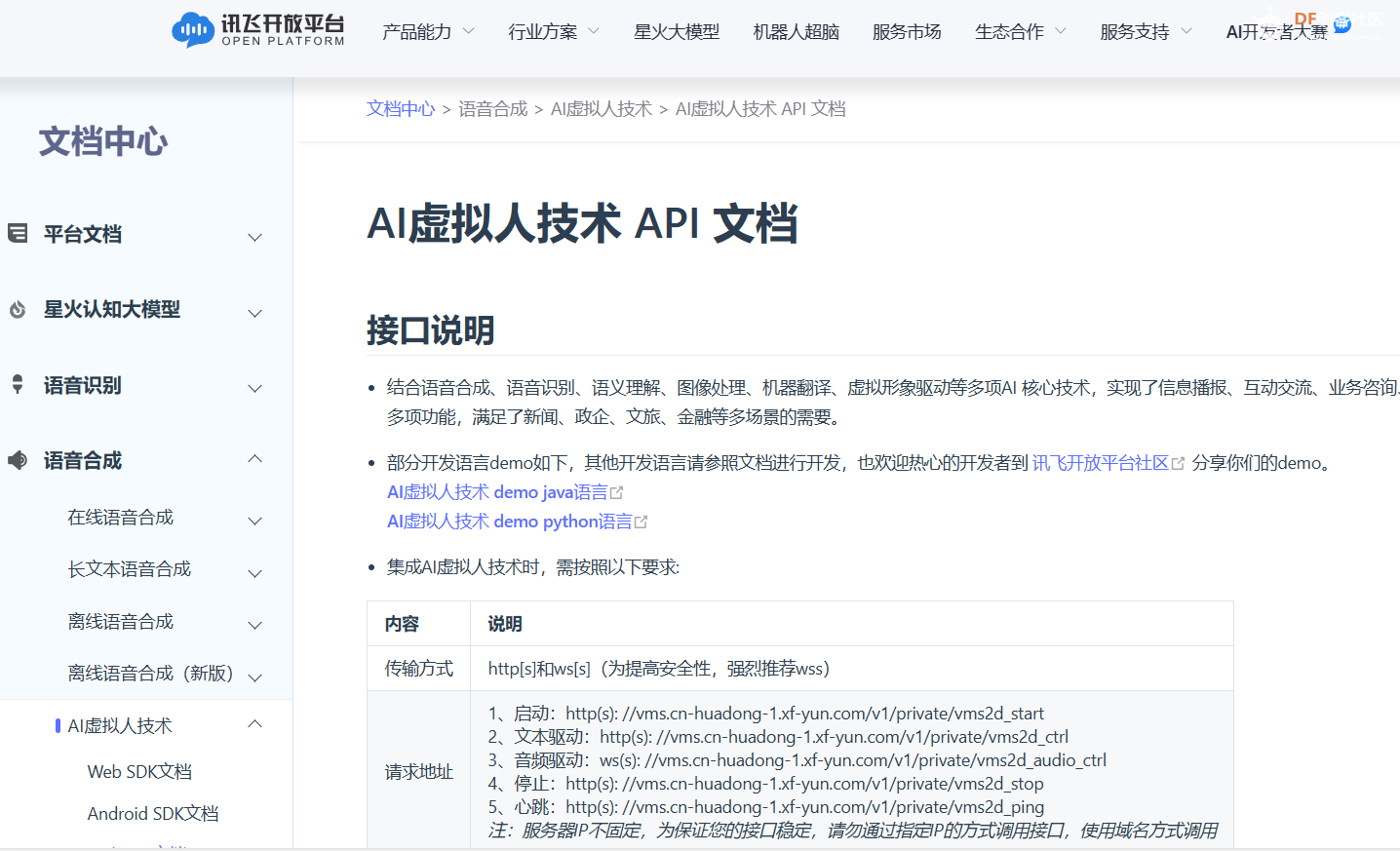
【下载Python-Demo】
AI虚拟人技术 API 文档提供了Python开发语言的demo:AI虚拟人技术 API 文档 | 讯飞开放平台文档中心 (xfyun.cn)
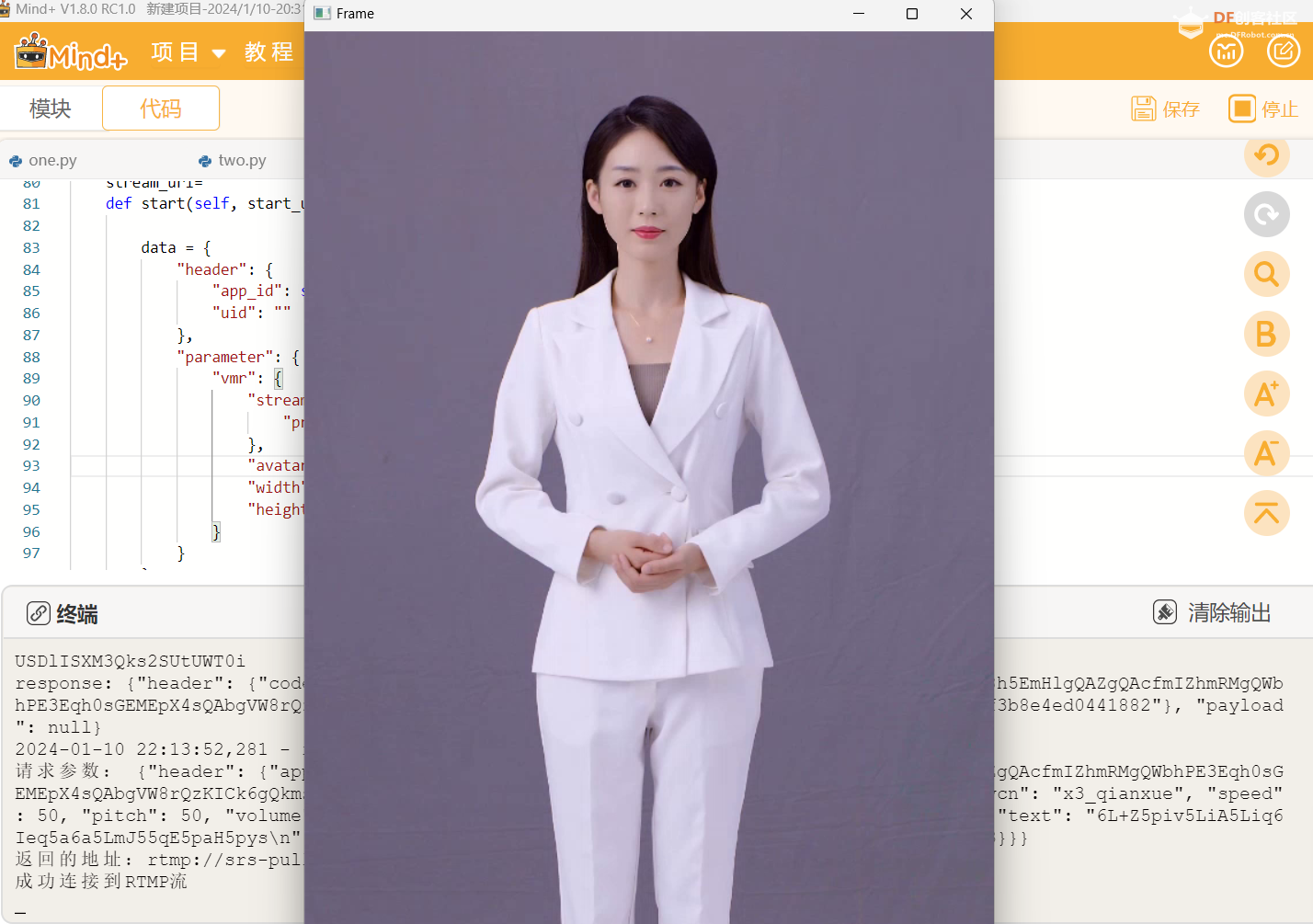
【电脑Mind+中测试】
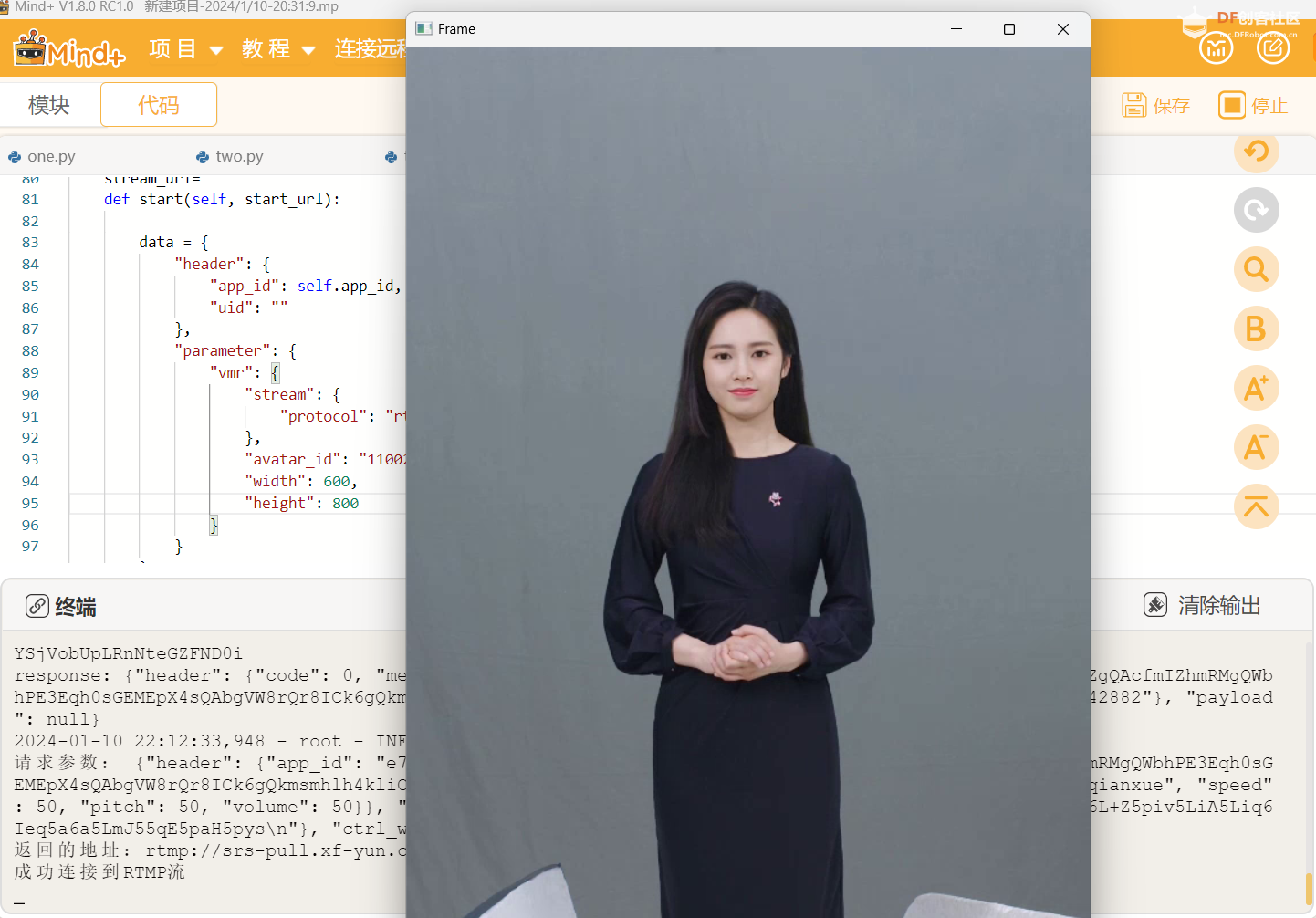
将文本上传给讯飞平台,使用Opencv库拉取讯飞虚拟人的RTMP流,进行播放。并使用讯飞语音合成,同时播放语音。
修改“avatar_id”更换虚拟人形象。
- "avatar_id": "110021007",#110017006 110021007
文本驱动“text_ctrl”,增加“action”参数,控制虚拟人“动作”。
- # 文本驱动
- def text_ctrl(self, text_url, session, text,action):
- # 合成文本
- encode_str = base64.encodebytes(text.encode("UTF8"))
- txt = encode_str.decode()
- if action==1:
- #value="A_RLH_introduced_O"
- value="A_RLH_emphasize_O"
- elif action==2:
- #value="A_RH_good_O"
- value="A_RH_encourage_O"
- action_text='{"avatar":[{"type": "action","value": "'+value+'","wb": 0}]}'
- action_text=base64.encodebytes(action_text.encode("UTF8"))
- action_text=action_text.decode()
- print(value)
- #action_text=""
- data = {
- "header": {
- "app_id": self.app_id,
- "session": session,
- "uid": ""
- },
- "parameter": {
- "tts": {
- "vcn": "x3_qianxue",
- "speed": 50,
- "pitch": 50,
- "volume": 50
- }
- },
- "payload": {
- "text": {
- "encoding": "utf8",
- "status": 3,
- "text": txt
- },
- "ctrl_w": {
- "encoding": "utf8",
- "format": "json",
- "status": 3,
- "text":action_text
- }
- }
- }
- self.get_url_data(text_url, data)
- print("请求参数:",json.dumps(data))
完整代码:
-
- #!/usr/bin/env python3
- # -*- coding: utf-8 -*-
- # @Author : iflytek
-
- import requests
- import json
- import base64
- import hashlib
- import time
- from urllib.parse import urlencode
- import hmac
- from datetime import datetime
- from wsgiref.handlers import format_date_time
- from time import mktime
- from ws4py.client.threadedclient import WebSocketClient
- import logging
- import cv2
- from df_xfyun_speech import XfTts
- import pygame
-
-
- pygame.mixer.init()
-
- text = ""
- action=0
-
- logging.basicConfig(format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', level=logging.INFO)
-
- ################init 参数######################
- HOST = "vms.cn-huadong-1.xf-yun.com"
- # 音频驱动参数
- STATUS_FIRST_FRAME = 0 # 第一帧的标识
- STATUS_CONTINUE_FRAME = 1 # 中间帧标识
- STATUS_LAST_FRAME = 2 # 最后一帧的标识
- # 用户参数,相关参数注意修改
-
-
- appId = "******************"
- apiKey ="******************"
- apiSecret = "******************"
- options = {}
-
- tts = XfTts(appId, apiKey, apiSecret, options)
- ###############################################
- APP_ID = "******************"
- API_SECRET = "******************"
- API_KEY = "******************"
-
- class RequestParam(object):
-
- def __init__(self):
- self.host = HOST
- self.app_id = APP_ID
- self.api_key = API_KEY
- self.api_secret = API_SECRET
- # 生成鉴权的url
- def assemble_auth_url(self, path, method='POST', schema='http'):
- params = self.assemble_auth_params(path, method)
- # 请求地址
- request_url = "%s://"%schema + self.host + path
- # 拼接请求地址和鉴权参数,生成带鉴权参数的url
- auth_url = request_url + "?" + urlencode(params)
- return auth_url
-
- # 生成鉴权的参数
- def assemble_auth_params(self, path, method):
- # 生成RFC1123格式的时间戳
- format_date = format_date_time(mktime(datetime.now().timetuple()))
- # 拼接字符串
- signature_origin = "host: " + self.host + "\n"
- signature_origin += "date: " + format_date + "\n"
- signature_origin += method+ " " + path + " HTTP/1.1"
- # 进行hmac-sha256加密
- signature_sha = hmac.new(self.api_secret.encode('utf-8'), signature_origin.encode('utf-8'),
- digestmod=hashlib.sha256).digest()
- signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
- # 构建请求参数
- authorization_origin = 'api_key="%s", algorithm="%s", headers="%s", signature="%s"' % (
- self.api_key, "hmac-sha256", "host date request-line", signature_sha)
- # 将请求参数使用base64编码
- authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
- # 将请求的鉴权参数组合为字典
- params = {
- "host": self.host,
- "date": format_date,
- "authorization": authorization
- }
- return params
-
-
- class VmsApi(RequestParam):
- # 接口data请求参数,字段具体含义见官网文档
- # 启动
- stream_url=""
- def start(self, start_url):
-
- data = {
- "header": {
- "app_id": self.app_id,
- "uid": ""
- },
- "parameter": {
- "vmr": {
- "stream": {
- "protocol": "rtmp"
- },
- "avatar_id": "110021007",#110017006 110021007
- "width": 600,
- "height": 800
- }
- }
- }
- url_data = self.get_url_data(start_url, data)
- session = ''
- if url_data:
- session = url_data.get('header', {}).get('session', '')
- self.stream_url = url_data.get('header', {}).get('stream_url', '拉流地址获取失败')
- print("拉流地址:%s" %self.stream_url)
- return session
-
- # 心跳
- def ping(self, ping_url, session):
-
- data = {
- "header": {
- "app_id": self.app_id,
- "uid":"",
- "session": session
- }
- }
-
- self.get_url_data(ping_url, data)
-
- # 停止
- def stop(self, stop_url, session):
- data = {
- "header": {
- "app_id": self.app_id,
- "session": session,
- "uid":""
- }
- }
- self.get_url_data(stop_url, data)
-
- # 文本驱动
- def text_ctrl(self, text_url, session, text,action):
- # 合成文本
- encode_str = base64.encodebytes(text.encode("UTF8"))
- txt = encode_str.decode()
- if action==1:
- #value="A_RLH_introduced_O"
- value="A_RLH_emphasize_O"
- elif action==2:
- #value="A_RH_good_O"
- value="A_RH_encourage_O"
- action_text='{"avatar":[{"type": "action","value": "'+value+'","wb": 0}]}'
- action_text=base64.encodebytes(action_text.encode("UTF8"))
- action_text=action_text.decode()
- print(value)
- #action_text=""
- data = {
- "header": {
- "app_id": self.app_id,
- "session": session,
- "uid": ""
- },
- "parameter": {
- "tts": {
- "vcn": "x3_qianxue",
- "speed": 50,
- "pitch": 50,
- "volume": 50
- }
- },
- "payload": {
- "text": {
- "encoding": "utf8",
- "status": 3,
- "text": txt
- },
- "ctrl_w": {
- "encoding": "utf8",
- "format": "json",
- "status": 3,
- "text":action_text
- }
- }
- }
- self.get_url_data(text_url, data)
- print("请求参数:",json.dumps(data))
-
- # 音频驱动
- def audio_ctrl(self, audio_url, session, audio_file):
- auth_audio_url = self.assemble_auth_url(audio_url, 'GET', 'ws')
- ws = AudioCtrl(auth_audio_url, session, audio_file)
- ws.connect()
- ws.run_forever()
-
- def get_url_data(self, url, data):
- auth_url = self.assemble_auth_url(url)
- print("示例url:",auth_url)
- headers = {'Content-Type': 'application/json'}
- try:
- result = requests.post(url=auth_url, headers=headers, data=json.dumps(data))
- result = json.loads(result.text)
- print("response:",json.dumps(result))
- code = result.get('header', {}).get('code')
- if code == 0:
- logging.info("%s 接口调用成功" % url)
- return result
- else:
- logging.error("%s 接口调用失败,错误码:%s" % (url, code))
- return {}
- except Exception as e:
- logging.error("%s 接口调用异常,错误详情:%s" %(url, e) )
- return {}
-
-
- # websocket 音频驱动
- class AudioCtrl(WebSocketClient):
-
- def __init__(self, url, session, file_path):
- super().__init__(url)
- self.file_path = file_path
- self.session = session
- self.app_id = APP_ID
-
- # 收到websocket消息的处理
- def received_message(self, message):
- message = message.__str__()
- try:
- res = json.loads(message)
- print("response:",json.dumps(res))
- # 音频驱动接口返回状态码
- code = res.get('header', {}).get('code')
- # 状态码为0,音频驱动接口调用成功
- if code == 0:
- logging.info("音频驱动接口调用成功")
- # 状态码非0,音频驱动接口调用失败, 相关错误码参考官网文档
- else:
- logging.info("音频驱动接口调用失败,返回状态码: %s" % code)
- except Exception as e:
- logging.info("音频驱动接口调用失败,错误详情:%s" % e)
-
- # 收到websocket错误的处理
- def on_error(self, error):
- logging.error(error)
-
- # 收到websocket关闭的处理
- def closed(self, code, reason=None):
- logging.info('音频驱动:websocket关闭')
-
- # 收到websocket连接建立的处理
- def opened(self):
- logging.info('音频驱动:websocket连接建立')
- frame_size = 1280 # 每一帧音频大小
- interval = 0.04 # 发送音频间隔(单位:s)
- status = STATUS_FIRST_FRAME # 音频的状态信息,标识音频是第一帧,还是中间帧、最后一帧
- count = 1
- with open(self.file_path, 'rb') as file:
- while True:
- buffer = file.read(frame_size)
- if len(buffer) < frame_size:
- status = STATUS_LAST_FRAME
- # 第一帧处理
- if status == STATUS_FIRST_FRAME:
- self.send_frame(status, buffer, count)
- status = STATUS_CONTINUE_FRAME
- # 中间帧处理
- elif status == STATUS_CONTINUE_FRAME:
- self.send_frame(status, buffer, count)
-
- # 最后一帧处理
- elif status == STATUS_LAST_FRAME:
- self.send_frame(status, buffer, count)
- break
- count += 1
- # 音频采样间隔
- time.sleep(interval)
-
- # 发送音频
- def send_frame(self, status, audio_buffer, seq):
- data = {
- "header": {
- "app_id": self.app_id,
- "session": self.session,
- "status": status,
- "uid":""
- },
- "payload": {
- "audio": {
- "encoding": "raw",
- "sample_rate": 16000,
- "status": status,
- "seq": seq,
- "audio": base64.encodebytes(audio_buffer).decode("utf-8")
- }
- }
- }
- json_data = json.dumps(data)
- print("请求参数:",json_data)
- self.send(json_data)
-
-
-
-
-
-
- if __name__ == "__main__":
- vms = VmsApi()
- start_url = "/v1/private/vms2d_start"
- print("启动")
- session = vms.start(start_url)
-
-
- if session:
- # 文本驱动,自定义文本内容
- time.sleep(10)
- ping_url = "/v1/private/vms2d_ping"
- print("\n文本驱动")
-
- text_url = "/v1/private/vms2d_ctrl"
-
- print("返回的地址:"+vms.stream_url)
- if vms.stream_url!="":
- rtmp_url =vms.stream_url
- cap = cv2.VideoCapture(rtmp_url)
- cap.set(cv2.CAP_PROP_FRAME_WIDTH,600)
- cap.set(cv2.CAP_PROP_FRAME_HEIGHT,800)
-
-
- if not cap.isOpened():
- print("无法连接到RTMP流")
- else:
- print("成功连接到RTMP流")
- bs=0
- while True:
- for i in range(3):
- ret, frame = cap.read()
- ret, frame = cap.read()
- #frame = cv2.resize(frame,( 240, 320))
-
- if not ret:
- break
- cv2.imshow("Windows", frame)
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
-
-
- if cv2.waitKey(1) & 0xFF == ord('a'):
- action=1
- text="大家好,我是讯飞虚拟人!"
-
- vms.text_ctrl(text_url, session, text,action)
- tts.synthesis(text, "speech.wav")
- pygame.mixer.Sound("speech.wav").play()
-
-
- if cv2.waitKey(1) & 0xFF == ord('b'):
- action=2
- text="这个程序写的真好,你真棒!"
-
- vms.text_ctrl(text_url, session, text,action)
- tts.synthesis(text, "speech.wav")
- pygame.mixer.Sound("speech.wav").play()
-
-
-
-
-
-
- # 停止
- time.sleep(10)
- print("\n停止")
- stop_url = "/v1/private/vms2d_stop"
- vms.stop(stop_url, session)
-
演示视频
【行空板文本驱动】
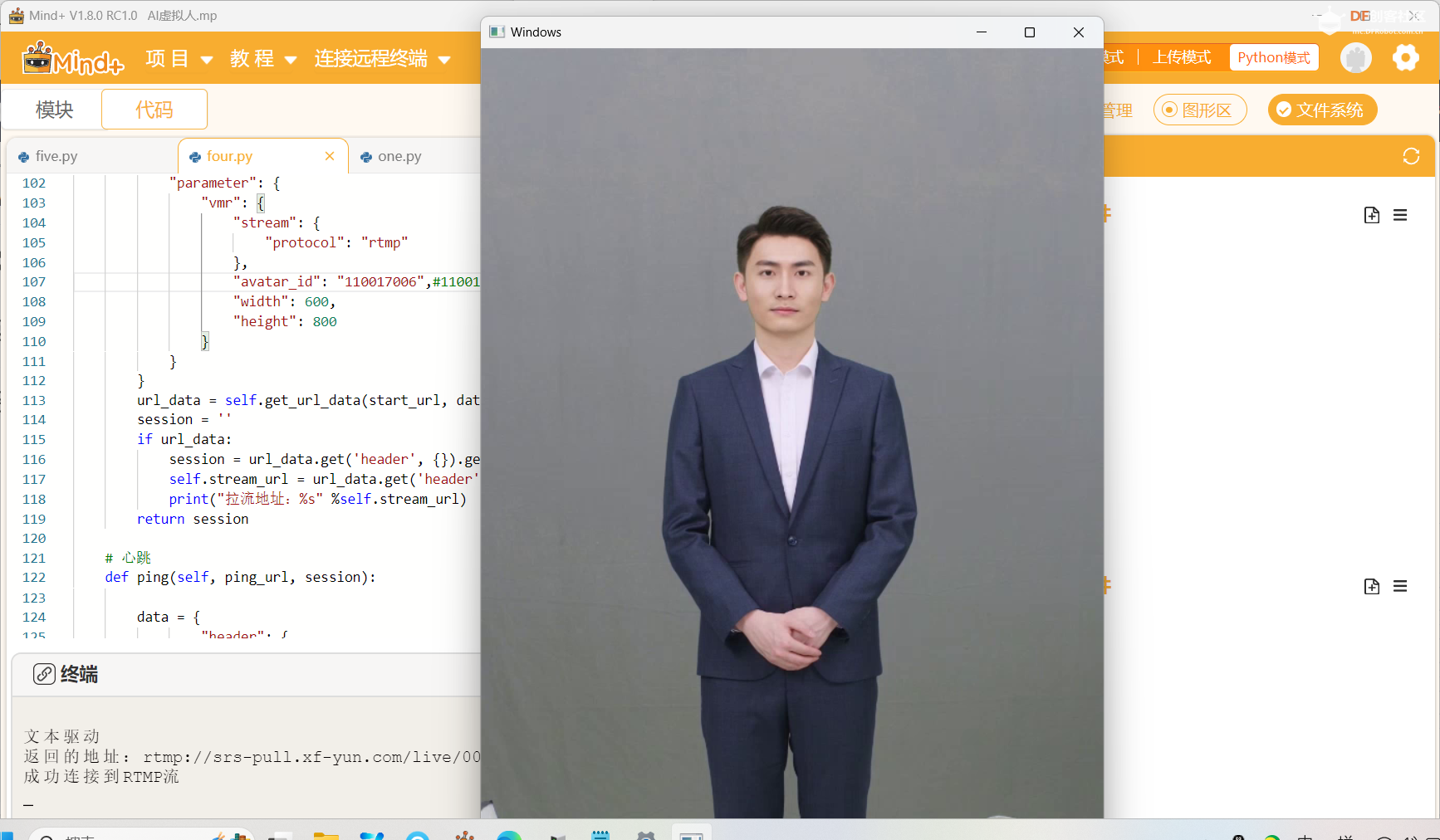
两个按钮分别接22和24引脚,使用两个按钮进行文本驱动控制虚拟人。文本一:“大家好,我是讯飞虚拟人!”,文本二:“这个程序写的真好,你真棒!”,并使用语音合成,通过蓝牙音箱播放语音。
- p_p22_in=Pin(Pin.P22, Pin.IN)
- p_p24_in=Pin(Pin.P24, Pin.IN)
在“终端”中使用“bluetoothctl”配置并连接蓝牙音箱。
Python程序代码
-
- #!/usr/bin/env python3
- # -*- coding: utf-8 -*-
- # @Author : iflytek
-
- import requests
- import json
- import base64
- import hashlib
- import time
- from urllib.parse import urlencode
- import hmac
- from datetime import datetime
- from wsgiref.handlers import format_date_time
- from time import mktime
- from ws4py.client.threadedclient import WebSocketClient
- import logging
- import cv2
- from pinpong.extension.unihiker import *
- from pinpong.board import Board,Pin
- from df_xfyun_speech import XfTts
-
- from unihiker import GUI
- u_gui=GUI()
- from unihiker import Audio
- u_audio = Audio()
- appId = "******************"
- apiKey ="******************"
- apiSecret = "******************"
- options = {}
-
- tts = XfTts(appId, apiKey, apiSecret, options)
- Board().begin()
- p_p22_in=Pin(Pin.P22, Pin.IN)
- p_p24_in=Pin(Pin.P24, Pin.IN)
- text = ""
- action=0
-
- logging.basicConfig(format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', level=logging.INFO)
-
- ################init 参数######################
- HOST = "vms.cn-huadong-1.xf-yun.com"
- # 音频驱动参数
- STATUS_FIRST_FRAME = 0 # 第一帧的标识
- STATUS_CONTINUE_FRAME = 1 # 中间帧标识
- STATUS_LAST_FRAME = 2 # 最后一帧的标识
- # 用户参数,相关参数注意修改
-
- APP_ID = "******************"
- API_SECRET = "******************"
- API_KEY = "******************"
- ###############################################
-
-
- class RequestParam(object):
-
- def __init__(self):
- self.host = HOST
- self.app_id = APP_ID
- self.api_key = API_KEY
- self.api_secret = API_SECRET
- # 生成鉴权的url
- def assemble_auth_url(self, path, method='POST', schema='http'):
- params = self.assemble_auth_params(path, method)
- # 请求地址
- request_url = "%s://"%schema + self.host + path
- # 拼接请求地址和鉴权参数,生成带鉴权参数的url
- auth_url = request_url + "?" + urlencode(params)
- return auth_url
-
- # 生成鉴权的参数
- def assemble_auth_params(self, path, method):
- # 生成RFC1123格式的时间戳
- format_date = format_date_time(mktime(datetime.now().timetuple()))
- # 拼接字符串
- signature_origin = "host: " + self.host + "\n"
- signature_origin += "date: " + format_date + "\n"
- signature_origin += method+ " " + path + " HTTP/1.1"
- # 进行hmac-sha256加密
- signature_sha = hmac.new(self.api_secret.encode('utf-8'), signature_origin.encode('utf-8'),
- digestmod=hashlib.sha256).digest()
- signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
- # 构建请求参数
- authorization_origin = 'api_key="%s", algorithm="%s", headers="%s", signature="%s"' % (
- self.api_key, "hmac-sha256", "host date request-line", signature_sha)
- # 将请求参数使用base64编码
- authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
- # 将请求的鉴权参数组合为字典
- params = {
- "host": self.host,
- "date": format_date,
- "authorization": authorization
- }
- return params
-
-
- class VmsApi(RequestParam):
- # 接口data请求参数,字段具体含义见官网文档
- # 启动
- stream_url=""
- def start(self, start_url):
-
- data = {
- "header": {
- "app_id": self.app_id,
- "uid": ""
- },
- "parameter": {
- "vmr": {
- "stream": {
- "protocol": "rtmp"
- },
- "avatar_id": "110021007",
- "width": 300,
- "height": 400
- }
- }
- }
- url_data = self.get_url_data(start_url, data)
- session = ''
- if url_data:
- session = url_data.get('header', {}).get('session', '')
- self.stream_url = url_data.get('header', {}).get('stream_url', '拉流地址获取失败')
- print("拉流地址:%s" %self.stream_url)
- return session
-
- # 心跳
- def ping(self, ping_url, session):
-
- data = {
- "header": {
- "app_id": self.app_id,
- "uid":"",
- "session": session
- }
- }
-
- self.get_url_data(ping_url, data)
-
- # 停止
- def stop(self, stop_url, session):
- data = {
- "header": {
- "app_id": self.app_id,
- "session": session,
- "uid":""
- }
- }
- self.get_url_data(stop_url, data)
-
- # 文本驱动
- def text_ctrl(self, text_url, session, text,action):
- # 合成文本
- encode_str = base64.encodebytes(text.encode("UTF8"))
- txt = encode_str.decode()
- if action==1:
- #value="A_RLH_introduced_O"
- value="A_RLH_emphasize_O"
- elif action==2:
- #value="A_RH_good_O"
- value="A_RH_encourage_O"
- action_text='{"avatar":[{"type": "action","value": "'+value+'","wb": 0}]}'
- action_text=base64.encodebytes(action_text.encode("UTF8"))
- action_text=action_text.decode()
- print(value)
- #action_text=""
- data = {
- "header": {
- "app_id": self.app_id,
- "session": session,
- "uid": ""
- },
- "parameter": {
- "tts": {
- "vcn": "x3_qianxue",
- "speed": 50,
- "pitch": 50,
- "volume": 50
- }
- },
- "payload": {
- "text": {
- "encoding": "utf8",
- "status": 3,
- "text": txt
- },
- "ctrl_w": {
- "encoding": "utf8",
- "format": "json",
- "status": 3,
- "text":action_text
- }
- }
- }
- self.get_url_data(text_url, data)
- print("请求参数:",json.dumps(data))
-
- # 音频驱动
- def audio_ctrl(self, audio_url, session, audio_file):
- auth_audio_url = self.assemble_auth_url(audio_url, 'GET', 'ws')
- ws = AudioCtrl(auth_audio_url, session, audio_file)
- ws.connect()
- ws.run_forever()
-
- def get_url_data(self, url, data):
- auth_url = self.assemble_auth_url(url)
- print("示例url:",auth_url)
- headers = {'Content-Type': 'application/json'}
- try:
- result = requests.post(url=auth_url, headers=headers, data=json.dumps(data))
- result = json.loads(result.text)
- print("response:",json.dumps(result))
- code = result.get('header', {}).get('code')
- if code == 0:
- logging.info("%s 接口调用成功" % url)
- return result
- else:
- logging.error("%s 接口调用失败,错误码:%s" % (url, code))
- return {}
- except Exception as e:
- logging.error("%s 接口调用异常,错误详情:%s" %(url, e) )
- return {}
-
-
- # websocket 音频驱动
- class AudioCtrl(WebSocketClient):
-
- def __init__(self, url, session, file_path):
- super().__init__(url)
- self.file_path = file_path
- self.session = session
- self.app_id = APP_ID
-
- # 收到websocket消息的处理
- def received_message(self, message):
- message = message.__str__()
- try:
- res = json.loads(message)
- print("response:",json.dumps(res))
- # 音频驱动接口返回状态码
- code = res.get('header', {}).get('code')
- # 状态码为0,音频驱动接口调用成功
- if code == 0:
- logging.info("音频驱动接口调用成功")
- # 状态码非0,音频驱动接口调用失败, 相关错误码参考官网文档
- else:
- logging.info("音频驱动接口调用失败,返回状态码: %s" % code)
- except Exception as e:
- logging.info("音频驱动接口调用失败,错误详情:%s" % e)
-
- # 收到websocket错误的处理
- def on_error(self, error):
- logging.error(error)
-
- # 收到websocket关闭的处理
- def closed(self, code, reason=None):
- logging.info('音频驱动:websocket关闭')
-
- # 收到websocket连接建立的处理
- def opened(self):
- logging.info('音频驱动:websocket连接建立')
- frame_size = 1280 # 每一帧音频大小
- interval = 0.04 # 发送音频间隔(单位:s)
- status = STATUS_FIRST_FRAME # 音频的状态信息,标识音频是第一帧,还是中间帧、最后一帧
- count = 1
- with open(self.file_path, 'rb') as file:
- while True:
- buffer = file.read(frame_size)
- if len(buffer) < frame_size:
- status = STATUS_LAST_FRAME
- # 第一帧处理
- if status == STATUS_FIRST_FRAME:
- self.send_frame(status, buffer, count)
- status = STATUS_CONTINUE_FRAME
- # 中间帧处理
- elif status == STATUS_CONTINUE_FRAME:
- self.send_frame(status, buffer, count)
-
- # 最后一帧处理
- elif status == STATUS_LAST_FRAME:
- self.send_frame(status, buffer, count)
- break
- count += 1
- # 音频采样间隔
- time.sleep(interval)
-
- # 发送音频
- def send_frame(self, status, audio_buffer, seq):
- data = {
- "header": {
- "app_id": self.app_id,
- "session": self.session,
- "status": status,
- "uid":""
- },
- "payload": {
- "audio": {
- "encoding": "raw",
- "sample_rate": 16000,
- "status": status,
- "seq": seq,
- "audio": base64.encodebytes(audio_buffer).decode("utf-8")
- }
- }
- }
- json_data = json.dumps(data)
- print("请求参数:",json_data)
- self.send(json_data)
-
-
-
-
- if __name__ == "__main__":
- vms = VmsApi()
- start_url = "/v1/private/vms2d_start"
- print("启动")
- session = vms.start(start_url)
-
-
- if session:
- # 文本驱动,自定义文本内容
- time.sleep(10)
- ping_url = "/v1/private/vms2d_ping"
- print("\n文本驱动")
-
- text_url = "/v1/private/vms2d_ctrl"
-
- print("返回的地址:"+vms.stream_url)
- if vms.stream_url!="":
- rtmp_url =vms.stream_url
- cap = cv2.VideoCapture(rtmp_url)
- cap.set(cv2.CAP_PROP_FRAME_WIDTH,240)
- cap.set(cv2.CAP_PROP_FRAME_HEIGHT,320)
- cv2.namedWindow('Windows', cv2.WINDOW_NORMAL)
- cv2.setWindowProperty('Windows', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
-
- if not cap.isOpened():
- print("无法连接到RTMP流")
- else:
- print("成功连接到RTMP流")
- bs=0
- while True:
- for i in range(3):
- ret, frame = cap.read()
- ret, frame = cap.read()
- frame = cv2.resize(frame,( 240, 320))
-
- if not ret:
- break
- cv2.imshow("Windows", frame)
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
-
-
- if (p_p22_in.read_digital()==True):
- action=1
- text="大家好,我是讯飞虚拟人"
- tts.synthesis(text, "speech.wav")
- u_audio.start_play("speech.wav")
- vms.text_ctrl(text_url, session, text,action)
-
- if (p_p24_in.read_digital()==True):
- action=2
- text="这个程序写的真好,你真棒"
- tts.synthesis(text, "speech.wav")
- u_audio.start_play("speech.wav")
- vms.text_ctrl(text_url, session, text,action)
-
-
-
-
-
-
-
- # 停止
- time.sleep(10)
- print("\n停止")
- stop_url = "/v1/private/vms2d_stop"
- vms.stop(stop_url, session)
-
演示视频
【语音对话】
使用“讯飞语音识别”,将用户语音识别成文本与“星火认识大模型”进行对话,将大模型反馈的结果送给虚拟人,同时利用讯飞语音合成播放语音。(文本长时,口型最后有些对不上,大家共同交流学习)
1.演示视频
2.测试程序代码
(1)服务侧设置60秒超时,要求客户端每间隔一段时间发起一次心跳进行保活,否则停止会话。-
- if time.time()-temtime>10:
- temtime=time.time()
- # 心跳
- print("\n心跳")
- ping_url = "/v1/private/vms2d_ping"
- vms.ping(ping_url, session)
-
(2)使用多线程,同步录音。
- from threading import Thread
(3)使用全局变量result1,判断文本驱动是否成功,同步播放合成语音。(4)完整代码
-
- #!/usr/bin/env python3
- # -*- coding: utf-8 -*-
- # @Author : iflytek
- import listening
- import requests
- import json
- import base64
- import hashlib
- import time
- from urllib.parse import urlencode
- import hmac
- from datetime import datetime
- from wsgiref.handlers import format_date_time
- from time import mktime
- from ws4py.client.threadedclient import WebSocketClient
- import logging
- import cv2
- from pinpong.extension.unihiker import *
- from pinpong.board import Board,Pin
- from df_xfyun_speech import XfTts
- from df_xfyun_speech import XfIat
-
- from threading import Thread
- from unihiker import Audio
- import SparkApi
- u_audio = Audio()
- appId = "*********************"
- apiKey ="*********************"
- apiSecret = "*********************"
- options = {}
-
- business_args = {"aue":"raw","vcn":"x4_xiaoxuan","tte":"utf8","speed":50,"volume":50,"pitch":50,"bgs":0}
- options["business_args"] = business_args
- iat = XfIat(appId, apiKey, apiSecret)
- tts = XfTts(appId, apiKey, apiSecret, options)
-
- appid2 ="*********************" #填写控制台中获取的 APPID 信息
- api_secret2 = "*********************" #填写控制台中获取的 APISecret 信息
- api_key2 ="*********************" #填写控制台中获取的 APIKey 信息
-
- #用于配置大模型版本,默认“general/generalv2”
- domain = "generalv3" # v1.5版本
- # domain = "generalv2" # v2.0版本
- #云端环境的服务地址
- Spark_url = "ws://spark-api.xf-yun.com/v3.1/chat" # v1.5环境的地址
- # Spark_url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0环境的地址
-
- text =[]
-
- # length = 0
-
- def getText(role,content):
- jsoncon = {}
- jsoncon["role"] = role
- jsoncon["content"] = content
- text.append(jsoncon)
- return text
-
- def getlength(text):
- length = 0
- for content in text:
- temp = content["content"]
- leng = len(temp)
- length += leng
- return length
-
- def checklen(text):
- while (getlength(text) > 8000):
- del text[0]
- return text
- def task():
- global result1
- listening.listen()
- Input= iat.recognition("record.wav")
- print(Input)
- if Input!="":
- question = checklen(getText("user",Input))
- SparkApi.answer =""
- print("星火:",end = "")
- SparkApi.main(appid2,api_key2,api_secret2,Spark_url,domain,question)
- if SparkApi.answer!="":
- getText("assistant",SparkApi.answer)
- tts.synthesis(SparkApi.answer, "speech.wav")
- time.sleep(1)
- text1=SparkApi.answer
-
- result1=vms.text_ctrl(text_url, session, text1)
-
-
- else:
- print("语音识别为空")
-
- action=0
-
- logging.basicConfig(format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', level=logging.INFO)
-
- ################init 参数######################
- HOST = "vms.cn-huadong-1.xf-yun.com"
- # 音频驱动参数
- STATUS_FIRST_FRAME = 0 # 第一帧的标识
- STATUS_CONTINUE_FRAME = 1 # 中间帧标识
- STATUS_LAST_FRAME = 2 # 最后一帧的标识
- # 用户参数,相关参数注意修改
-
- APP_ID = "*********************"
- API_SECRET = "*********************"
- API_KEY = "*********************"
- ###############################################
-
-
- class RequestParam(object):
-
- def __init__(self):
- self.host = HOST
- self.app_id = APP_ID
- self.api_key = API_KEY
- self.api_secret = API_SECRET
- # 生成鉴权的url
- def assemble_auth_url(self, path, method='POST', schema='http'):
- params = self.assemble_auth_params(path, method)
- # 请求地址
- request_url = "%s://"%schema + self.host + path
- # 拼接请求地址和鉴权参数,生成带鉴权参数的url
- auth_url = request_url + "?" + urlencode(params)
- return auth_url
-
- # 生成鉴权的参数
- def assemble_auth_params(self, path, method):
- # 生成RFC1123格式的时间戳
- format_date = format_date_time(mktime(datetime.now().timetuple()))
- # 拼接字符串
- signature_origin = "host: " + self.host + "\n"
- signature_origin += "date: " + format_date + "\n"
- signature_origin += method+ " " + path + " HTTP/1.1"
- # 进行hmac-sha256加密
- signature_sha = hmac.new(self.api_secret.encode('utf-8'), signature_origin.encode('utf-8'),
- digestmod=hashlib.sha256).digest()
- signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
- # 构建请求参数
- authorization_origin = 'api_key="%s", algorithm="%s", headers="%s", signature="%s"' % (
- self.api_key, "hmac-sha256", "host date request-line", signature_sha)
- # 将请求参数使用base64编码
- authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
- # 将请求的鉴权参数组合为字典
- params = {
- "host": self.host,
- "date": format_date,
- "authorization": authorization
- }
- return params
-
-
- class VmsApi(RequestParam):
- # 接口data请求参数,字段具体含义见官网文档
- # 启动
- stream_url=""
- def start(self, start_url):
-
- data = {
- "header": {
- "app_id": self.app_id,
- "uid": ""
- },
- "parameter": {
- "vmr": {
- "stream": {
- "protocol": "rtmp"
- },
- "avatar_id": "110021007",
- "width": 600,
- "height": 800
- }
- }
- }
- url_data = self.get_url_data(start_url, data)
- session = ''
- if url_data:
- session = url_data.get('header', {}).get('session', '')
- self.stream_url = url_data.get('header', {}).get('stream_url', '拉流地址获取失败')
- print("拉流地址:%s" %self.stream_url)
- return session
-
- # 心跳
- def ping(self, ping_url, session):
-
- data = {
- "header": {
- "app_id": self.app_id,
- "uid":"",
- "session": session
- }
- }
-
- self.get_url_data(ping_url, data)
-
- # 停止
- def stop(self, stop_url, session):
- data = {
- "header": {
- "app_id": self.app_id,
- "session": session,
- "uid":""
- }
- }
- self.get_url_data(stop_url, data)
-
- # 文本驱动
- def text_ctrl(self, text_url, session, text):
- # 合成文本
- encode_str = base64.encodebytes(text.encode("UTF8"))
- txt = encode_str.decode()
- value="A_RLH_emphasize_O"
-
- action_text='{"avatar":[{"type": "action","value": "'+value+'","wb": 0}]}'
- action_text=base64.encodebytes(action_text.encode("UTF8"))
- action_text=action_text.decode()
- print(value)
- #action_text=""
- data = {
- "header": {
- "app_id": self.app_id,
- "session": session,
- "uid": ""
- },
- "parameter": {
- "tts": {
- "vcn": "x4_xiaoxuan",
- "speed": 50,
- "pitch": 50,
- "volume": 50
- }
- },
- "payload": {
- "text": {
- "encoding": "utf8",
- "status": 3,
- "text": txt
- },
- "ctrl_w": {
- "encoding": "utf8",
- "format": "json",
- "status": 3,
- "text":action_text
- }
- }
- }
- result=""
- result=self.get_url_data(text_url, data)
- if result!="":
- return 1
- else:
- return 0
- print("请求参数:",json.dumps(data))
-
- # 音频驱动
- def audio_ctrl(self, audio_url, session, audio_file):
- auth_audio_url = self.assemble_auth_url(audio_url, 'GET', 'ws')
- ws = AudioCtrl(auth_audio_url, session, audio_file)
- ws.connect()
- ws.run_forever()
-
- def get_url_data(self, url, data):
- auth_url = self.assemble_auth_url(url)
- print("示例url:",auth_url)
- headers = {'Content-Type': 'application/json'}
- try:
- result = requests.post(url=auth_url, headers=headers, data=json.dumps(data))
- result = json.loads(result.text)
- print("response:",json.dumps(result))
- code = result.get('header', {}).get('code')
- if code == 0:
- logging.info("%s 接口调用成功" % url)
- return result
- else:
- logging.error("%s 接口调用失败,错误码:%s" % (url, code))
- return {}
- except Exception as e:
- logging.error("%s 接口调用异常,错误详情:%s" %(url, e) )
- return {}
-
-
- # websocket 音频驱动
- class AudioCtrl(WebSocketClient):
-
- def __init__(self, url, session, file_path):
- super().__init__(url)
- self.file_path = file_path
- self.session = session
- self.app_id = APP_ID
-
- # 收到websocket消息的处理
- def received_message(self, message):
- message = message.__str__()
- try:
- res = json.loads(message)
- print("response:",json.dumps(res))
- # 音频驱动接口返回状态码
- code = res.get('header', {}).get('code')
- # 状态码为0,音频驱动接口调用成功
- if code == 0:
- logging.info("音频驱动接口调用成功")
- # 状态码非0,音频驱动接口调用失败, 相关错误码参考官网文档
- else:
- logging.info("音频驱动接口调用失败,返回状态码: %s" % code)
- except Exception as e:
- logging.info("音频驱动接口调用失败,错误详情:%s" % e)
-
- # 收到websocket错误的处理
- def on_error(self, error):
- logging.error(error)
-
- # 收到websocket关闭的处理
- def closed(self, code, reason=None):
- logging.info('音频驱动:websocket关闭')
-
- # 收到websocket连接建立的处理
- def opened(self):
- logging.info('音频驱动:websocket连接建立')
- frame_size = 1280 # 每一帧音频大小
- interval = 0.04 # 发送音频间隔(单位:s)
- status = STATUS_FIRST_FRAME # 音频的状态信息,标识音频是第一帧,还是中间帧、最后一帧
- count = 1
- with open(self.file_path, 'rb') as file:
- while True:
- buffer = file.read(frame_size)
- if len(buffer) < frame_size:
- status = STATUS_LAST_FRAME
- # 第一帧处理
- if status == STATUS_FIRST_FRAME:
- self.send_frame(status, buffer, count)
- status = STATUS_CONTINUE_FRAME
- # 中间帧处理
- elif status == STATUS_CONTINUE_FRAME:
- self.send_frame(status, buffer, count)
-
- # 最后一帧处理
- elif status == STATUS_LAST_FRAME:
- self.send_frame(status, buffer, count)
- break
- count += 1
- # 音频采样间隔
- time.sleep(interval)
-
- # 发送音频
- def send_frame(self, status, audio_buffer, seq):
- data = {
- "header": {
- "app_id": self.app_id,
- "session": self.session,
- "status": status,
- "uid":""
- },
- "payload": {
- "audio": {
- "encoding": "raw",
- "sample_rate": 16000,
- "status": status,
- "seq": seq,
- "audio": base64.encodebytes(audio_buffer).decode("utf-8")
- }
- }
- }
- json_data = json.dumps(data)
- print("请求参数:",json_data)
- self.send(json_data)
-
-
-
- temtime=time.time()
- if __name__ == "__main__":
- vms = VmsApi()
- start_url = "/v1/private/vms2d_start"
- print("启动")
- session = vms.start(start_url)
- result1=0
- text.clear
- if session:
- # 文本驱动,自定义文本内容
- time.sleep(10)
- ping_url = "/v1/private/vms2d_ping"
- print("\n文本驱动")
-
- text_url = "/v1/private/vms2d_ctrl"
-
- print("返回的地址:"+vms.stream_url)
- if vms.stream_url!="":
- rtmp_url =vms.stream_url
- cap = cv2.VideoCapture(rtmp_url)
- cap.set(cv2.CAP_PROP_FRAME_WIDTH,600)
- cap.set(cv2.CAP_PROP_FRAME_HEIGHT,800)
-
-
- if not cap.isOpened():
- print("无法连接到RTMP流")
- else:
- print("成功连接到RTMP流")
- bs=0
- while True:
-
- ret, frame = cap.read()
-
-
- if not ret:
- break
- cv2.imshow("Windows", frame)
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
-
- if cv2.waitKey(1) & 0xFF == ord('a'):
- print("启动线程")
- time.sleep(3)
- t1 = Thread(target=task)
- t1.start()
- if result1==1:
- result1=0
- u_audio.start_play("speech.wav")
- #t1._stop()
-
- if time.time()-temtime>10:
- temtime=time.time()
- # 心跳
- print("\n心跳")
- ping_url = "/v1/private/vms2d_ping"
- vms.ping(ping_url, session)
-
|






 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 创客造
创客造
 编辑选择奖
编辑选择奖
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






