|
5030| 0
|
[官方资料] NVIDIA Jetson Nano 2GB 系列文章(37):多网路模型合成功能 |
|
很多人惊艳于 deepstream-app 里面那个可以同时检测到车子的颜色、品牌、种类的实验,这的确是个非常亮眼的应用,在开发包范例中的 deepstream-test2 就是这项功能的范例代码,同样是以 test1 为基础,维持相同的视频文件输入与显示器输出的部分,只修改“推理计算(nvinfer)”的部分。 本文的内容就是开始涉及到 DeepStream 推理计算的组合应用,在 test1 系列中使用单一的 4 类检测器是非常简单的,当然这种使用的比例会是最高的,因为大部分的应用都是针对性,包括口罩识别、人/车/路标识别、水果识别等等。 但是有很多特殊的应用并非单一网络模型所能应付的,例如前面提过的车牌识别,还有一些医疗成像的肿瘤识别、商业用途的表情识别、年龄识别等,都需要在特定标的物里面再去找进一步的特征。 就像车牌识别必须先找到“车”这个标的物,再从车里面去找出“车牌”的位置,再将车牌里的字符一一识别出来;肿瘤分析必须先找到特定“器官”,然后在器官范围内去比对肿瘤块;表情识别需要先找到“人脸”,再从人脸的特征去区分表情。以上描述的用途,是需要多种神经网络共同协作,来完成一完整的识别任务。 常规的处理思路会使用多次解析的方式来处理,如果面对图像的时候还算是单纯的,但面对视频数据的时候,这种多次解析的方法就很难满足“实时性”的要求,这就是一个需要突破的难点。 面对这样的困扰,DeepStream 提供这种多网络合成的方式,能非常有效地在一次解析的过程中完成所有的推理计算,这样就能确保执行的效率,下面就要告诉大家 DeepStream 是如何做到这些工作的。 deepstream-test2 项目重点解说
deepstream-test2 代码还是以 deepstream-test1 为基础,如果不熟悉的请先看看本系列前面的文章。这里维持 test1 的视频文件输入与显示器输出方式不变,在“Car/Person/Bicycle/RoadSign”四种物件分类的推理识别基础上,为“Car”物件再添加“颜色/品牌/车型”这三种分类属性(如下图),因此总体来说就需要“一个检测器(detector)”与“三个分类器(classifier)”来共同完成这项任务。  可能有人会问,那是否能在“Person”或“RoadSign”上面增加分类器?例如将前者再添加“男/女”、“老/少”分类,对后者再添加“限制类”、“指示类”、“警告类”的属性呢?这当然是可以的,只要你能找到合适的模型文件来搭配,或者得自己重新收集数据集进行模型训练,然后再提供对应的配置文件。 与 test1 范例中所不同的地方,在 test2 范例在“pgie”这个“nvinfer”元素之外,又添加“sgie1/sgie2/sgie3”这3个推理计算的元素,总共四个推理器的内容如下:  这个过程有个比较特殊的地方,就是在”主推理器(这里是个检测器)”与“次推理器(这里是三个分类器)”之间,需要透过“追踪器(tracker)”进行串联,这里有个很重要的原因,因为次推理器是以主推理器的“范围图像”去进行分类推理,包括颜色、品牌、车型等等,而追踪器可以协助记录主推理器所找到的“图像范围”,将这个局部的数据传送给次推理器去进行计算,这样才能建立好“主次”之间的关联。 因此我们会发现,只要需要进行这种“主次结合”的方式,必定需要调用“追踪器”这个元件来扮演角色,这个在 deepstream-app 里面也是存在的,但是这里会延伸出另一个问题,就是调用追踪器是会影响性能的,在 DeepStream 追踪器里面,目前支持 NVDCF、KLT 与 IOU 三种算法,其中 NVDCF 算法的性能最差,KLT 在准确性与性能的综合表现较好,因此大部分的范例中都选择使用 KLT 追踪器。 附带说明的一点,就是追踪器插件接受来自上游组件的 NV12-或 RGBA 格式的帧数据,并将输入缓冲区转换为低层库所需格式的缓冲区,再将宽度和高度转换为跟踪器要求的宽度和高度,这需要将输入帧缓冲区转换为底层库请求的格式,例如 KLT 使用 Luma 专用格式、NvDCF 使用 NV12 或 RGBA 格式,IOU 则不需要缓冲区。 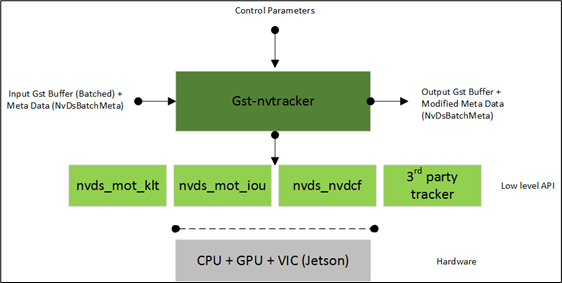 上图是 nvtracker 插件的工作示意图,详细的内容请自行参考开发手册:https://docs.nvidia.com/metropolis/deepstream/dev-guide/text/DS_plugin_gst-nvtracker.html 好了,前面已经将整体原理说明的差不多,接下来就看看 test2 与 test1 的 Python 代码中的差异部分,这样就更能掌握这部分的实际运作内涵。 deepstream-test2 代码修改部分 如同前面所提到的,这个代码主要修改的部分,就是在 pgie 与 nvvideoconvert 之间,添加 tracker 与 sgie 1~3 这四个元件,其他修改的部分几乎都在处理 tracker 的部分,包括一开始需要为追踪器是否保存追踪数据的。 以上就是 test2 与 test1 在创建元件与设置参数部分的一些代码修改的部分,至于管道创建与连接的部分,自己就能看懂,这里就不浪费篇幅去说明。 最后还有一部分,就是在函数 osd_sink_pad_buffer_probe 里面,第 126~164 行有一代码,不过下面注释内容表明 l_user.data 与 user_meta.user_meta_data 在这里并不做处理,我们也试过将“if(past_tracking_meta[0]==1):”下面整段代码全部删除,并不影响 test2 范例的执行与输出结果。 修改设定文件与执行 最后在执行之前,看一下 5 个配置文件的内容,发现原本的设定以“INT8”精度模式进行推理,可以看到文件里的“network-mode”都设置为“1”,如果在 Jetson Nano(含 2GB)上执行时,建议将这些模式都改成“FP16”模式,除了将所有“network-mode”都改成“2”之外,再把每个加速引擎的“xxx_int8.engine”改成“xxx_fp16.engine”。 虽然不改变这个设定值也能正常工作,差别就在于如果要重复测试的时候,就得花费更多时间去重新生成“xxx_fp16.engine”加速引擎,如果改成“fp16”模式的话,就只需要生成一次就行,第二次再执行的时候就会非常快速启动。 好了,一切就绪之后,就可以体验一下这个多模型合成功能的效果,请执行以下指令: 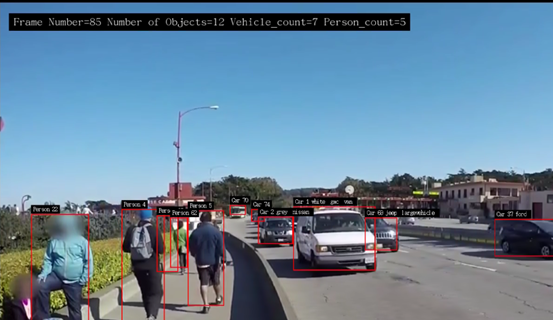 在屏幕上方会出现该帧的检测结果,不过这里只显示“Vehicle”与“Person”两个类别。图片中也能清楚看到每个物件都有个“追踪编号”,在 Car 物件上也有“颜色”、“厂牌”、“车型”等信息。 当我们回头再仔细看看这个范例的代码,会发现其实大部分要做的事情,就是把插件元件做合理的安排,然后就是“定义”、“创建”、“连接”,就几乎完成大部分的工作了。 |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






