本帖最后由 云天 于 2025-5-26 00:12 编辑
一、项目背景
- 在当今数字化时代,人工智能技术正以前所未有的速度改变着我们的生活和创作方式。作为一名创客,我一直对如何将人工智能技术与创意项目相结合充满兴趣。最近,我利用行空板和行空板M10扩展板,结合讯飞语音识别和硅基流动(SiliconFlow)的视频生成API,成功实现了一个“一句话生成视频”的项目。这个项目不仅展示了人工智能的强大功能,还体现了行空板M10扩展板在集成供电和功能扩展方面的优势。
- 随着人工智能技术的飞速发展,自然语言处理和图像生成技术已经逐渐成熟。讯飞语音识别技术在语音转文字方面表现出色,而硅基流动提供的视频生成API则能够根据文本描述生成相应的视频内容。结合这些技术,我希望能够通过行空板实现一个简单的“一句话生成视频”项目,让用户可以通过语音输入,生成一段视频。
二、硬件与软件准备
(一)硬件准备- 行空板:作为项目的主控板,负责运行程序和处理数据。集成麦克风用于语音输入,集成显示屏用于显示提示信息和视频内容。
- 行空板M10扩展板组合:包括电机IO扩展板、金手指扩展板和800mAh电池扩展板。在这个项目中,主要利用800mAh电池扩展板为行空板提供稳定的移动电源,确保项目可以在没有外部电源的情况下运行。
(二)软件准备- Mind+:用于图形化编程和上传代码到行空板。
- Python环境:行空板支持Python编程,Mind+软件的Python模式下,连接行空板并安装相关库。
- 讯飞语音识别SDK:用于将语音转换为文本。
- 硅基流动API:用于根据文本生成视频。
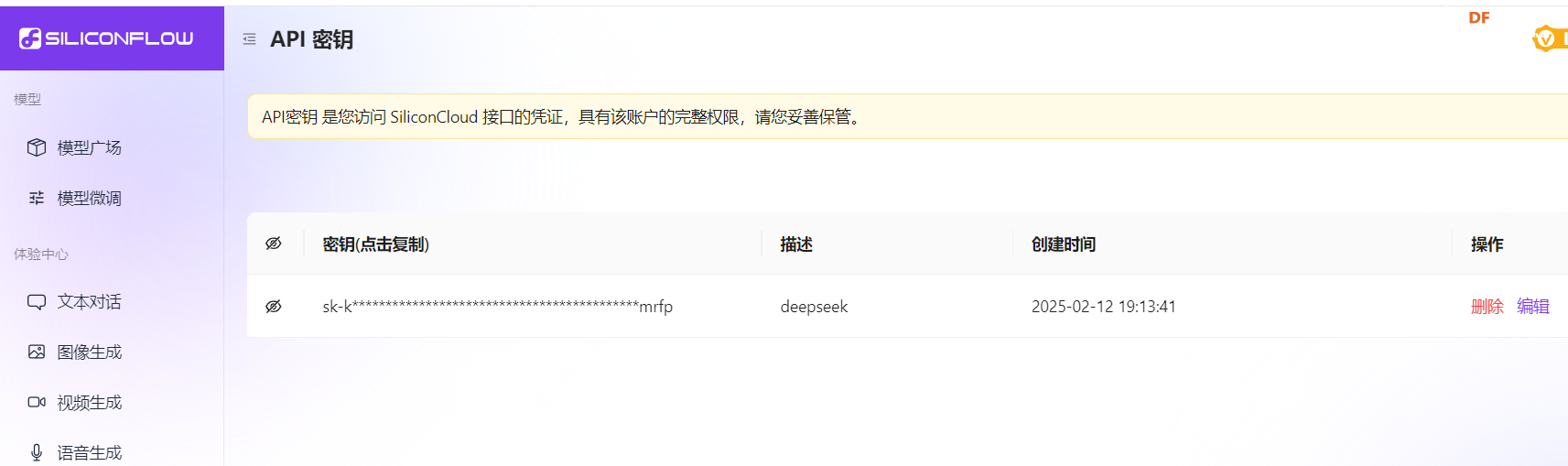
通过第三方的硅基流动注册获取API,如方便注册,使用我的邀请码注册:https://cloud.siliconflow.cn/i/KwyEBX3e,邀请码:KwyEBX3e。共同获取免费额度。如果不方便注册,可使用我的API:sk-kxwsrzianqfxsebnihblrgyyytrrtgvvdjvdiujcuvwymrfp。
三、项目实现
(一)语音识别
项目的第一步是通过麦克风录制语音,并利用讯飞语音识别技术将语音转换为文本。在行空板上,我使用了讯飞语音识别SDK,并设置了相应的APPID、APIKey和APISecret(注册获取)。通过按下按钮A开始录音,按下按钮B停止录音并开始识别。识别结果会显示在屏幕上。
(二)视频生成
识别出的文本将作为视频生成的输入。我使用了硅基流动提供的视频生成API,通过POST请求将文本描述发送到API服务器,并获取一个requestId。然后,通过另一个API接口查询视频生成的状态。当视频生成成功后,服务器会返回视频的URL。
(三)视频播放
获取到视频URL后,我使用OpenCV库在行空板上播放视频。OpenCV提供了强大的视频处理功能,可以方便地播放网络视频流。通过设置窗口属性,我将视频全屏显示在屏幕上。
四、程序代码
- # -*- coding: UTF-8 -*-
-
- # MindPlus
- # Python
- import json
- import time,sys
- sys.path.append("/root/mindplus/.lib/thirdExtension/liliang-xunfeiyuyin-thirdex")
- import xunfeiasr
- from unihiker import GUI
- from unihiker import Audio
- import requests
- import cv2
-
- # 定义API URL和请求头S
- url_submit = "https://api.siliconflow.cn/v1/video/submit"
- url_status = "https://api.siliconflow.cn/v1/video/status"
- headers = {
- "Authorization": "Bearer sk-kxwsrzianqfxsebnihblrgyyytrrtgvvdjvdiujcuvwymrfp",
- "Content-Type": "application/json"
- }
-
- # 初始化变量
- requestStatus = ""
- bs = 0
- payload = {}
- u_gui = GUI()
- u_audio = Audio()
-
- # 事件回调函数
- def on_buttona_click_callback():
- global u_audio,bs2
-
- 显示.config(text="开始录音")
- 显示.config(x=50)
- 显示.config(font_size=30)
- print("开始录音")
- time.sleep(0.1)
- u_audio.start_record("record.wav")
-
- def on_buttonb_click_callback():
- global u_audio, url_submit, url_status, headers, requestStatus, bs, payload,xunfeiasr
- u_audio.stop_record()
-
- 显示.config(text="开始识别")
- 显示.config(x=50)
- 显示.config(font_size=30)
- print("停止录音,开始识别")
- text = xunfeiasr.xunfeiasr(r"record.wav")
- time.sleep(3)
- 显示.config(x=0)
- 显示.config(font_size=20)
- print(f"识别结果:{text}")
- wrap_text(text)
-
- # 提交视频生成请求
- payload = {
- "model": "Wan-AI/Wan2.1-T2V-14B",
- "prompt": text,
- "negative_prompt": "模糊",
- "image_size": "960x960",
- "seed": 123
- }
- try:
- response = requests.post(url_submit, json=payload, headers=headers)
- response.raise_for_status() # 检查请求是否成功
- response_json = response.json()
- requestId = response_json.get("requestId")
- print(f"提交成功,requestId: {requestId}")
-
- # 查询视频生成状态
- payload = {"requestId": requestId}
- bs = 1
- except requests.exceptions.RequestException as e:
- print(f"提交请求失败:{e}")
- # 屏幕宽度(以像素为单位)
- SCREEN_WIDTH = 240
- # 字符宽度
- CHAR_WIDTH = 30
-
- def wrap_text(text):
- wrapped_text = ""
- current_line = ""
- current_line_width = 0
-
- for char in text:
- if char == '\r':
- # 如果遇到 \r,将当前行加入到 wrapped_text 中,并开始新的一行
- wrapped_text += current_line + "\n"
- current_line = ""
- current_line_width = 0
- else:
- # 检查当前行加上新字符是否超出屏幕宽度
- if current_line_width + CHAR_WIDTH > SCREEN_WIDTH:
- # 如果超出屏幕宽度,将当前行加入到 wrapped_text 中,并开始新的一行
- wrapped_text += current_line + "\n"
- current_line = char
- current_line_width = CHAR_WIDTH
- else:
- current_line += char
- current_line_width += CHAR_WIDTH
-
- # 添加最后一行
- if current_line:
- wrapped_text += current_line
- wrapped_text+="\r\r视频正在生成中……"
- 显示.config(text=wrapped_text)
- # 设置按键回调
- u_gui.on_a_click(on_buttona_click_callback)
- u_gui.on_b_click(on_buttonb_click_callback)
- u_gui.draw_text(text="行空板",x=60,y=20,font_size=30, color="#0000FF")
- 显示=u_gui.draw_text(text="一句话生成视频",x=20,y=100,font_size=20, color="#FF0000")
-
- # 设置讯飞语音识别参数
- xunfeiasr.xunfeiasr_set(APPID="*****", APISecret="*****", APIKey="*****")
- bs2=0
- # 主循环
- while True:
- if bs == 1:
- try:
- response = requests.post(url_status, json=payload, headers=headers)
- response.raise_for_status() # 检查请求是否成功
- response_json = response.json()
- requestStatus = response_json.get("status")
- print(f"查询状态:{requestStatus}")
-
- if requestStatus == "Succeed":
- bs = 0
- video_url = response_json['results']['videos'][0]['url']
- print(f"视频URL:{video_url}")
-
- # 播放视频
- cap = cv2.VideoCapture(video_url)
- if not cap.isOpened():
- print("无法打开视频流,请检查URL是否有效")
- else:
- print("成功打开视频流")
-
- # 创建窗口并设置窗口大小
- cv2.namedWindow('Video', cv2.WINDOW_NORMAL)
- #cv2.resizeWindow('Video', 240, 320) # 设置窗口大小为240x320
- cv2.setWindowProperty("Video", cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
- bs2=1
- last_frame = None # 用于保存最后一帧
-
- # 设置帧率(每秒25帧)
- fps = 25
- frame_delay = int(1000 / fps) # 每帧的显示时间(毫秒)
-
- # 循环读取视频帧
- while True:
- ret, frame = cap.read()
- if ret:
- last_frame = frame.copy() # 保存当前帧为最后一帧
- cv2.imshow('Video', frame)
- else:
- print("视频流播放完成")
- break
-
- if cv2.waitKey(frame_delay) == ord('q'):
- break
-
-
-
- # 释放资源
- cap.release()
- cv2.destroyAllWindows()
- except requests.exceptions.RequestException as e:
- print(f"查询状态失败:{e}")
- time.sleep(3) # 等待一段时间后重试
五、行空板M10扩展板的应用
- 行空板M10扩展板组合在这个项目中发挥了重要作用。800mAh电池扩展板为行空板提供了稳定的电源,使得项目可以在没有外部电源的情况下运行。这大大增加了项目的便携性和实用性。同时,金手指扩展板提供了更多的接口,可以方便地连接其他外设。
六、演示视频
生成过程耗时较长,大概4至6分钟。为显示效果,本视频做了特别处理。
七、项目总结
- 通过这个项目,我不仅实现了“一句话生成视频”的功能,还深入体会到了行空板M10扩展板的强大功能。它不仅提供了稳定的供电,还扩展了行空板的接口能力,使得项目更加灵活和多样化。未来,我将继续探索行空板和扩展板的更多可能性,尝试将更多的人工智能技术应用到创意项目中,创造出更多有趣的作品。
- 如果你也对这个项目感兴趣,不妨尝试一下。相信你会在实践中发现更多乐趣和可能性。
| 






 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶

 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 创客造
创客造
 编辑选择奖
编辑选择奖
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






