|
8259| 6
|
[平台测评] 【天天向上】OpenVINO学习笔记(一) |

|
【天天向上】OpenVINO学习笔记(三)使用 OpenVINO 的 OpenCV 库 【天天向上】OpenVINO学习笔记(二)运行python demo 【天天向上】OpenVINO学习笔记(四)目标检测模型 【天天向上】OpenVINO学习笔记(五)驾驶室内监控 【天天向上】OpenVINO学习笔记(六)Smart Classroom C++ Demo 【天天向上】OpenVINO学习笔记(七)C++ 演示 【天天向上】OpenVINO学习笔记(八)凝视估计演示 【天天向上】OpenVINO学习笔记(九)3d人体姿态估计测试 【天天向上】OpenVINO学习笔记(十)人脸识别+监控+计算棒 【天天向上】OpenVINO学习笔记(十一)网络摄像头使用 【天天向上】OpenVINO学习笔记(十二)测试真实环境识别效果 【运行范例】 OpenVINO范例-人体姿态分析 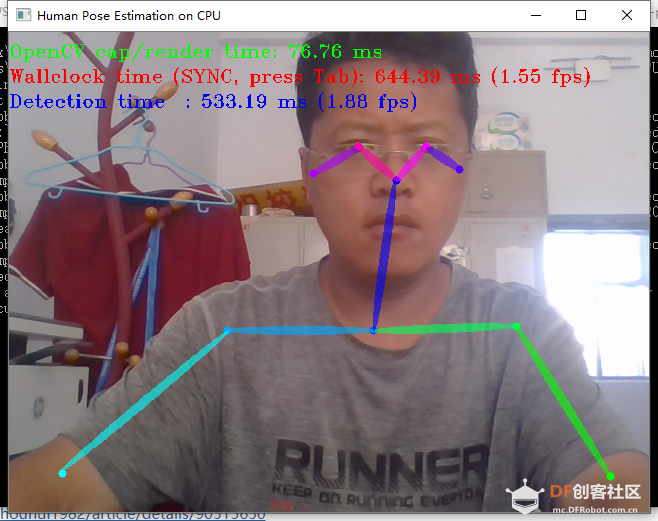 【演示视频-姿态识别】 (interactive_face_detection_demo.exe -i cam -m C:\Users\hp\Documents\Intel\intel\face-detection-0100\FP16-INT8\face-detection-0100.xml -d CPU) 【OpenVINO工具套件】 OpenVINO工具套件全称是Open Visual Inference & Neural Network Optimization,是Intel于2018年发布的,开源、商用免费、主要应用于计算机视觉、实现神经网络模型优化和推理计算(Inference)加速的软件工具套件。由于其商用免费,且可以把深度学习模型部署在英尔特CPU和集成GPU上,大大节约了显卡费用,所以越来越多的深度学习应用都使用OpenVINO工具套件做深度学习模型部署。 它支持tensorflow caffe mxnet等模型的转换,将这些模型的权重与网络结构转换成 .xml 与 .bin文件,它好比计算机语言编译器可以将多种语言编译成二进制代码。避免了开发人员为了同一个业务需求,在不同平台多次开发,多次部署,使用openvino,只需一次开发,就可以将模型部署在多个平台。openvino支持多种基础网络,多种目标检测算法,多种图像分割算法,支持rcnn,支持权重量化操作。 OpenVINO工具套件主要包括: Model Optimizer(模型优化器):用于优化神经网络模型的工具 Inference Engine(推理引擎):用于加速推理计算的软件包 通常一个完整的深度学习应用开发流程可以归结为三步: 用TensorFlow训练模型 用OpenVINO模型优化器优化模型 用OpenVINO推理引擎API开发用户应用程序 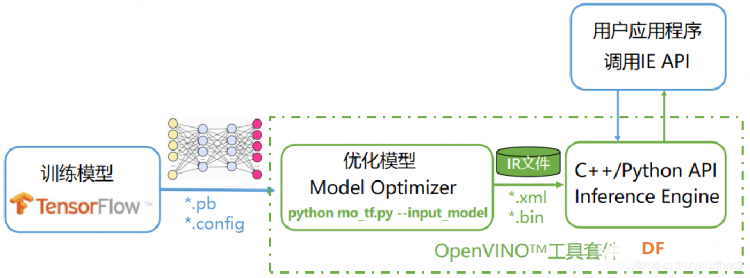 1、OpenVINO范例-超分辨率(super_resolution_demo) 2、OpenVINO范例-道路分割(segmentation_demo) 3、OpenVINO范例-汽车识别(security_barrier_camera_demo) 4、OpenVINO范例-人脸识别(interactive_face_detection_demo) 5、OpenVINO范例-人体姿态分析(human_pose_estimation_demo) 6、OpenVINO范例-行人车辆分析(pedestrian_tracker_demo)
【计算棒】 计算棒需要配合Intel出的OpenVINO推理框架,使用时首先需要将模型文件转换为OpenVINO的模型。OpenVINO目前支持Caffe、TensorFlow、MXNet等主流的深度学习框架。模型可以直接通过OpenVINO的转换工具进行转换。转换时需要输入网络输入节点的名称以及输入图片的大小,还有一点需要注意,NCS 2计算棒支持的是16位精度的浮点型数据,所以在转换时还需要加上”–data_type=FP16”。 OpenVINO框架中使用NCS 2计算棒和直接使用CPU性能差不多,使用CPU(Intel Core i5 4200M)时,检测一帧需要660ms,使用NCS2计算棒需要590ms。但是在 OpenVINO框架中使用CPU速度要比在MXNet中使用CPU快,MXNet中使用CPU检测一帧需要1.1s左右。OpenVINO前向计算能基本比mxnet框架快一倍。 【参考文档】 1、安装OpenVINO https://www.pianshen.com/article/6673625017/ https://blog.csdn.net/qq_36556893/article/details/81391468 2、OpenVINO 学习笔记(3):执行 OpenVINO Demos https://blog.csdn.net/u011385476/article/details/104769250 (1)”3.2 下载模型文件“中修改:python C:\IntelSWTools\openvino_2020.1.033\deployment_tools\tools\model_downloader\downloader.py --name human-pose-estimation-0001 为:C:\Program Files (x86)\IntelSWTools\openvino_2020.2.117\deployment_tools\tools\model_downloader>python downloader.py --name human-pose-estimation-0001 --output_dir C:\Users\zlzx\Documents\Intel 目录指定为自己的。 (2)"4、执行 human_pose_estimation_demo.exe"中修改human_pose_estimation_demo.exe -i C:\Users\LWL\Desktop\sample-videos-master\classroom.mp4 -m C:\Users\LWL\Desktop\human-pose-estimation-0001.xml -d CPU为:human_pose_estimation_demo.exe -i cam -m C:\Users\zlzx\Documents\Intel\intel\human-pose-estimation-0001\FP32\human-pose-estimation-0001.xml -d CPU 3、openVINO downloader.py下载全部模型命令 https://blog.csdn.net/zhouhui1982/article/details/90515650 4、使用CMD,由于目录比较长,可在文件夹内新建run.bat,内容为cmd.exe。双击运行。 5、OpenVINO Pre-Trained 预训练模型介绍 http://www.person168.com/?p=16701 |
|
import cv2 as cv # Load the model net = cv.dnn.readNet('face-detection-adas-0001.xml', 'face-detection-adas-0001.bin') # Specify target device net.setPreferableTarget(cv.dnn.DNN_TARGET_MYRIAD) # Read an image frame = cv.imread('/path/to/image') # Prepare input blob and perform an inference blob = cv.dnn.blobFromImage(frame, size=(672, 384), ddepth=cv.CV_8U) net.setInput(blob) out = net.forward() # Draw detected faces on the frame for detection in out.reshape(-1, 7): confidence = float(detection[2]) xmin = int(detection[3] * frame.shape[1]) ymin = int(detection[4] * frame.shape[0]) xmax = int(detection[5] * frame.shape[1]) ymax = int(detection[6] * frame.shape[0]) if confidence > 0.5: cv.rectangle(frame, (xmin, ymin), (xmax, ymax), color=(0, 255, 0)) # Save the frame to an image file cv.imwrite('out.png', frame) |
|
import cv2 as cv # Load the model net = cv.dnn.readNet('face-detection-adas-0001.xml', 'face-detection-adas-0001.bin') # Specify target device net.setPreferableTarget(cv.dnn.DNN_TARGET_MYRIAD) # Read an image camera = cv2.VideoCapture("rtsp://admin:HikCUALGW@192.168.31.241:554/Streaming/Channels/101") # Prepare input blob and perform an inference while True: text = "Unoccupied" # 获取当前帧并初始化occupied/unoccupied文本 (grabbed, frame) = camera.read() # 如果不能抓取到一帧,说明我们到了视频的结尾 if not grabbed: break frame = imutils.resize(frame, width=800) blob = cv.dnn.blobFromImage(frame, size=(672, 384), ddepth=cv.CV_8U) net.setInput(blob) out = net.forward() # Draw detected faces on the frame for detection in out.reshape(-1, 7): confidence = float(detection[2]) xmin = int(detection[3] * frame.shape[1]) ymin = int(detection[4] * frame.shape[0]) xmax = int(detection[5] * frame.shape[1]) ymax = int(detection[6] * frame.shape[0]) if confidence > 0.5: cv.rectangle(frame, (xmin, ymin), (xmax, ymax), color=(0, 255, 0)) cv2.imshow("contours", frame) key = cv2.waitKey(1) & 0xFF # 如果q键被按下,跳出循环 if key == ord("q"): break # 清理摄像机资源并关闭打开的窗口 camera.release() cv2.destroyAllWindows() |
|
FAILED: octave-resnet-50-0.125 octave-resnet-200-0.125 resnet-50 handwritten-score-recognition-0003 inception-resnet-v2-tf squeezenet1.1-caffe2 head-pose-estimation-adas-0001 vgg19-caffe2 gmcnn-places2-tf octave-resnext-50-0.25 yolo-v1-tiny-tf mobilenet-ssd densenet-169-tf faster_rcnn_inception_v2_coco ssd_mobilenet_v1_coco se-resnext-50 ssd_mobilenet_v1_fpn_coco ssdlite_mobilenet_v2 squeezenet1.1 vgg19 mobilenet-v2-1.4-224 mask_rcnn_resnet101_atrous_coco resnet-152 license-plate-recognition-barrier-0007 mobilenet-v1-0.50-160 efficientnet-b0 densenet-169 googlenet-v1-tf ssd_mobilenet_v2_coco resnet-18-pytorch colorization-v2-norebal ctpn mobilenet-v2 midasnet googlenet-v1 ssd512 octave-resnext-101-0.25 faster_rcnn_inception_resnet_v2_atrous_coco icnet-camvid-ava-sparse-30-0001 densenet-161 mobilenet-v1-1.0-224-tf efficientnet-b0_auto_aug mask_rcnn_inception_v2_coco googlenet-v4-tf facenet-20180408-102900 ssd300 yolo-v2-tiny-tf faster-rcnn-resnet101-coco-sparse-60-0001 densenet-201 mobilenet-v1-0.25-128 mobilenet-v1-0.50-224 single-human-pose-estimation-0001 densenet-121 efficientnet-b7_auto_aug Sphereface vgg16 octave-densenet-121-0.125 face-recognition-resnet50-arcface efficientnet-b7-pytorch se-resnet-152 human-pose-estimation-3d-0001 mtcnn-r densenet-121-caffe2 brain-tumor-segmentation-0001 face-detection-retail-0044 mask_rcnn_inception_resnet_v2_atrous_coco efficientnet-b5-pytorch resnet-50-pytorch densenet-161-tf se-resnet-101 densenet-121-tf octave-resnet-26-0.25 deeplabv3 resnet-50-caffe2 se-inception human-pose-estimation-0001 squeezenet1.0 mobilenet-v2-pytorch alexnet icnet-camvid-ava-0001 brain-tumor-segmentation-0002 mask_rcnn_resnet50_atrous_coco rfcn-resnet101-coco-tf face-recognition-mobilefacenet-arcface efficientnet-b5 octave-resnet-101-0.125 ctdet_coco_dlav0_384 se-resnet-50 se-resnext-101 yolo-v3-tf googlenet-v3-pytorch mtcnn-p resnet-50-tf caffenet efficientnet-b0-pytorch googlenet-v2 mobilenet-v1-1.0-224 faster_rcnn_resnet101_coco mobilenet-v2-1.0-224 ctdet_coco_dlav0_512 googlenet-v3 colorization-v2 face-recognition-resnet100-arcface i3d-rgb-tf octave-se-resnet-50-0.125 yolo-v2-tf mtcnn-o faster_rcnn_resnet50_coco vehicle-license-plate-detection-barrier-0123 resnet-101 face-recognition-resnet34-arcface |
|
python ./face_recognition_demo.py -m_fd C:\Users\hp\Documents\Intel\intel\face-detection-retail-0004\FP32\face-detection-retail-0004.xml -m_lm C:\Users\hp\Documents\Intel\intel\landmarks-regression-retail-0009\FP32\landmarks-regression-retail-0009.xml -m_reid C:\Users\hp\Documents\Intel\intel\face-reidentification-retail-0095\FP32\face-reidentification-retail-0095.xml -fg "D:/face_gallery" |



 沪公网安备31011502402448
沪公网安备31011502402448© 2013-2026 Comsenz Inc. Powered by Discuz! X3.4 Licensed

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶
 活跃会员
活跃会员
 宣传大使
宣传大使
 牛X认证
牛X认证
 创客造
创客造
 编辑选择奖
编辑选择奖
 志“童”道合
志“童”道合
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖
 编辑选择奖
编辑选择奖






